Hamza ZELMAT, TECH LEAD DATA
Dans le domaine du traitement des données, nous sommes souvent confrontés à des défis de transformation et d’orchestration, avec des volumes de données qui ne cessent de croître. Dans un monde parfait, il suffirait de cliquer sur un bouton pour que toutes les données soient transformées et organisées de manière idéale. Malheureusement, nous savons que la réalité est toute autre.
En tant que data engineer, il est important de se tenir informé de l’évolution constante des outils d’ingestion de données, dans un contexte où les entreprises doivent gérer des flux considérables d’informations. Certains outils peuvent aider et accélérer la conception de nouveaux pipelines de données en :
- Optimisant la qualité des données
- Facilitant la collaboration entre les équipes
- Améliorant la scalabilité de leurs solutions d’analyse de données.
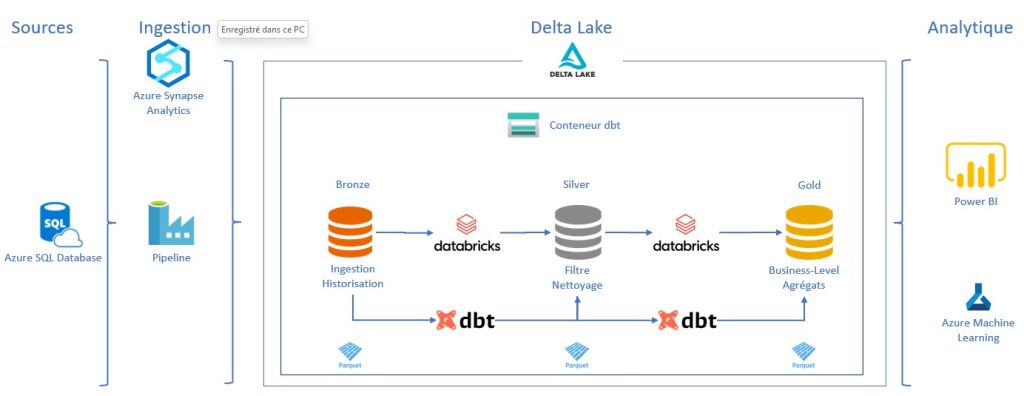
Dans cet article, nous présentons les atouts offerts par Databricks et dbt (Data Build Tool) pour concevoir aisément des transformations de données. Nous abordons la configuration conjointe des deux outils afin de proposer une solution exhaustive pour le traitement des données. Nous conclurons par un cas d’usage simple.
- dbt Core : version open-source de dbt, qui fournit les fonctionnalités de base pour la modélisation, le test et la documentation des données. dbt Core s’installe localement sur une machine ou serveur et s’utilise en ligne de commande.
- dbt Cloud : version hébergée et managée de dbt, proposée en tant que service (SaaS). dbt Cloud offre toutes les fonctionnalités de dbt Core, mais ajoute également des fonctionnalités avancées telles que l’interface graphique, l’orchestration intégrée, les déploiements automatisés et la gestion d’accès des utilisateurs.
- Databricks Runtime : Un environnement d’exécution optimisé qui inclut des bibliothèques et des extensions pour Apache Spark, permettant des performances accrues et une meilleure fiabilité.
- Databricks Workspace : Un environnement de développement collaboratif qui permet aux utilisateurs de créer des notebooks, d’exécuter des commandes et de partager des résultats avec leurs collègues.
- Connectivité des données : Databricks permet de se connecter à diverses sources de données, y compris les data lakes, les data warehouses, les bases de données relationnelles et non relationnelles, et les API.
- Delta Lake : Une couche de stockage open-source qui apporte de nouvelles fonctionnalités aux data lakes, telles que la gestion des transactions ACID, l’historique des versions
- Autoscaling et gestion des ressources : La plateforme Databricks permet l’autoscaling des clusters pour gérer efficacement les ressources en fonction de la charge de travail, optimisant ainsi les coûts et les performances.
- Sécurité et conformité : Databricks offre des fonctionnalités de sécurité avancées, telles que le chiffrement des données au repos et en transit, l’authentification unique (SSO), l’intégration avec les services d’identité et le contrôle d’accès basé sur les rôles (RBAC).
- Integration avec les écosystèmes cloud : Databricks s’intègre parfaitement avec les principales plateformes cloud (AWS, Azure et GCP), offrant une compatibilité avec les services de stockage, d’analyse et de machine learning de ces plateformes.
- Installer dbt et le connecteur Python pour Databricks
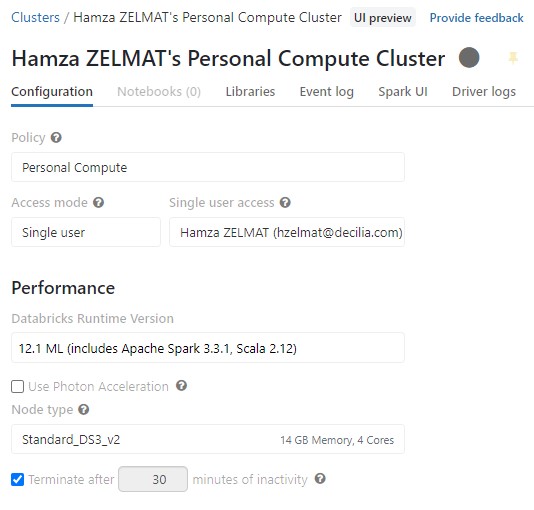
- Configurer un cluster Databricks
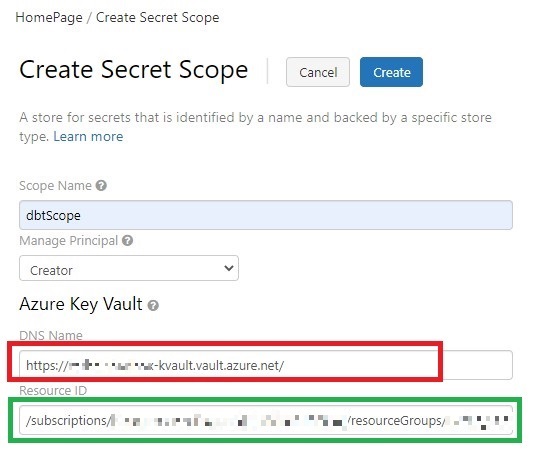
- Créer un profil dbt pour se connecter au cluster Databricks
- Écrire des modèles dbt pour extraire et transformer vos données
- Exécuter votre projet dbt
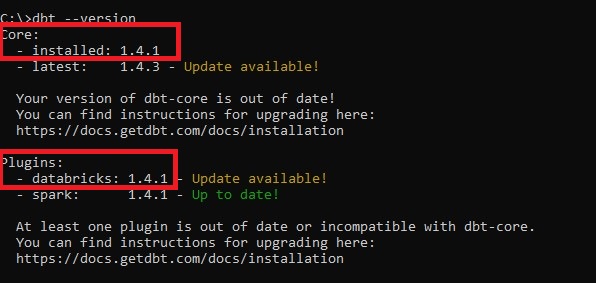
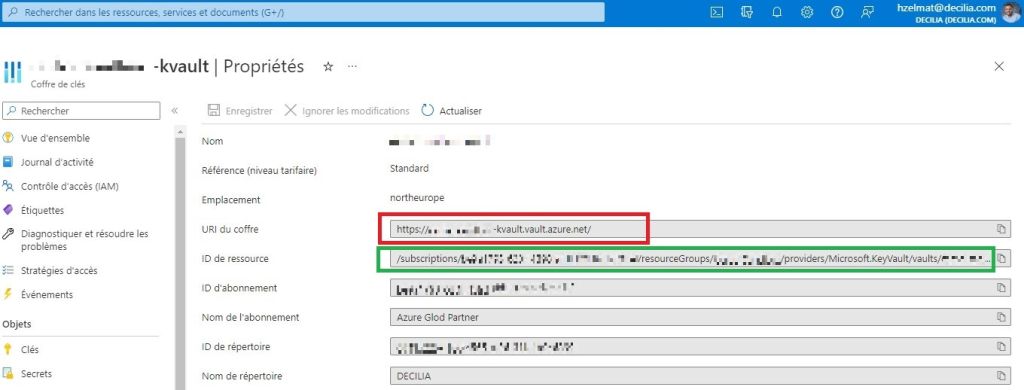
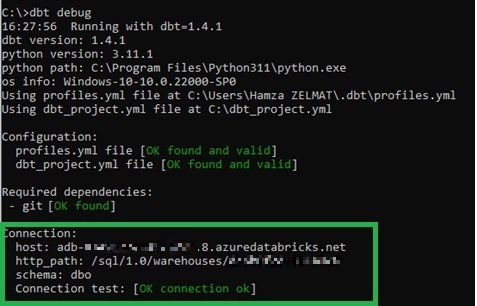
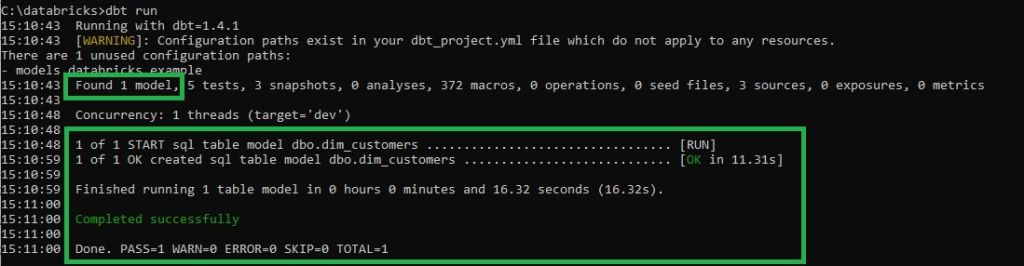
La configuration terminée, nous pouvons tester la connexion en exécutant la commande suivante depuis l’invite de commande Windows (Figure 6) :

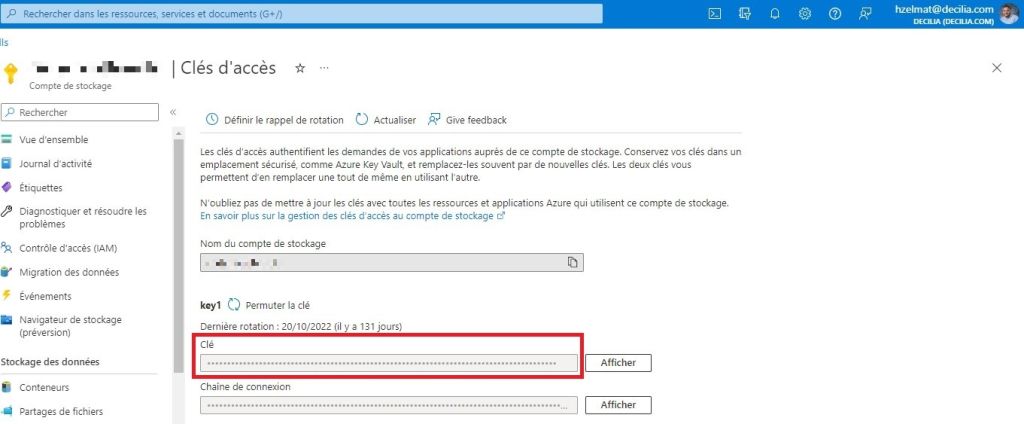
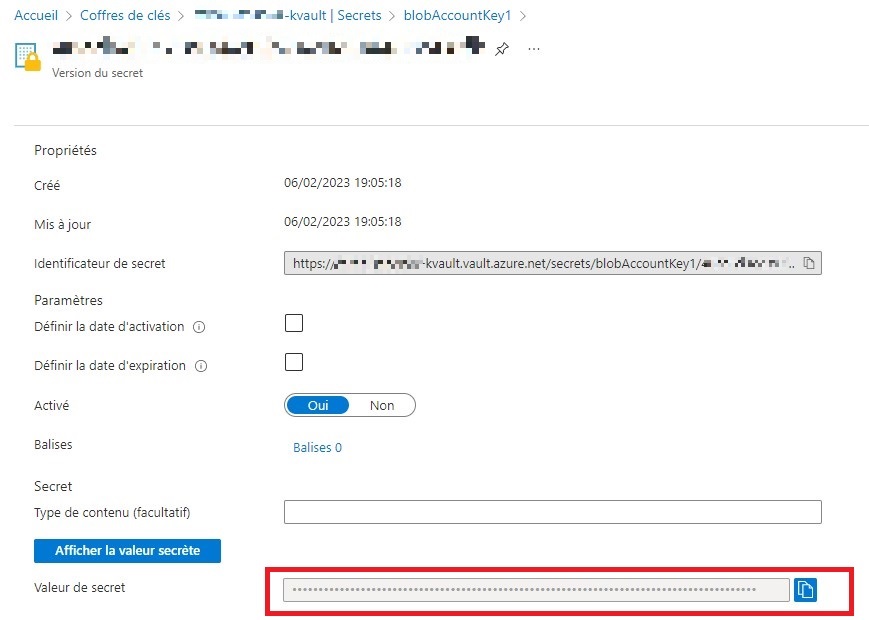
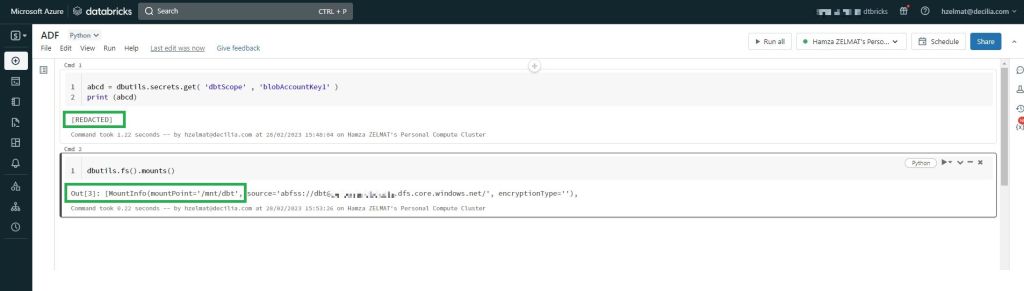
print (abcd)
dbutils.fs().mounts() list-scopes
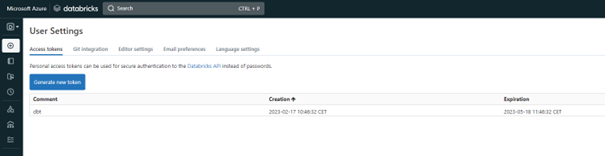
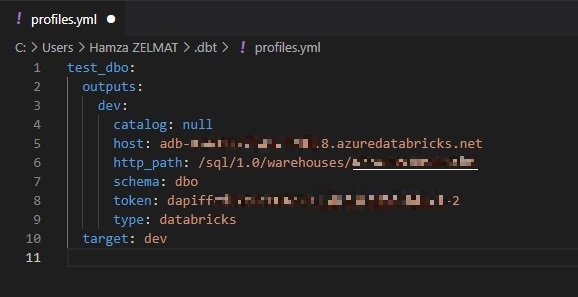
- Host: instance Databricks
- http_path: URL du cluster
- schema: schéma de la base de données
- token: token d’accès personnel de l’utilisateur à Databricks
- type: ressource utilisée (databricks, snowflake, redshift, …)
dbt debug
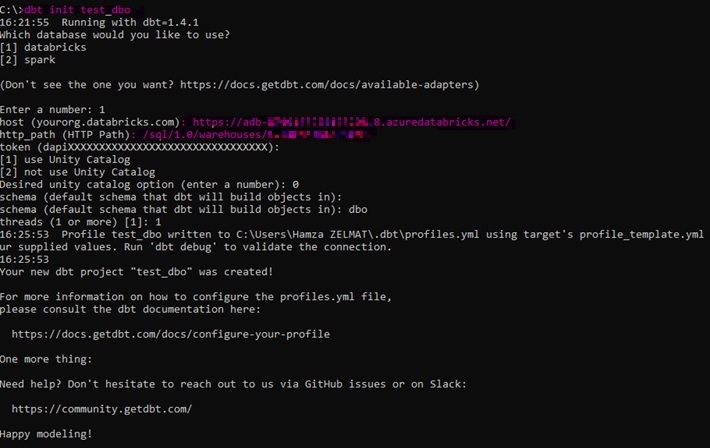
dbt init <nom_projet>
- analyses : ce répertoire contient des modèles dbt utilisés pour effectuer des analyses exploratoires de données. Les modèles d’analyse sont généralement moins structurés que les modèles de transformation de données et peuvent être utilisés pour explorer les données et générer des rapports.
- macros : ce répertoire contient des fichiers SQL réutilisables, appelés « macros », qui peuvent être invoqués dans des modèles dbt. Les macros peuvent effectuer des tâches telles que la conversion de formats de données ou l’agrégation de données et peuvent simplifier le processus de développement de modèles.
- models : c’est le répertoire principal où sont stockés tous les modèles dbt. Les modèles sont des fichiers SQL contenant des requêtes pour extraire, transformer et charger des données. Chaque modèle peut avoir une ou plusieurs dépendances avec d’autres modèles ou fichiers.
- seeds : ce répertoire contient des fichiers de données initiales, également appelées données de départ ou données d’amorçage. Les fichiers de données sont utilisés pour initialiser les tables d’un entrepôt de données avec des données de test ou des données de production. Les fichiers de données sont au format CSV, JSON, YAML ou SQL.
- snapshots : ce répertoire contient des modèles dbt qui créent des « snapshots » de nos tables dans leur état actuel. Les snapshots sont des copies des données dans une table à un moment précis et peuvent être utilisés pour suivre les changements dans les données au fil du temps. Les modèles de snapshot peuvent être planifiés pour s’exécuter régulièrement, créant ainsi un historique des données dans nos tables.
- tests : ce répertoire contient des modèles dbt utilisés pour tester la qualité des données dans un entrepôt de données. Les tests dbt peuvent vérifier des choses comme la conformité des données aux contraintes de base de données ou l’exactitude des agrégats de données.
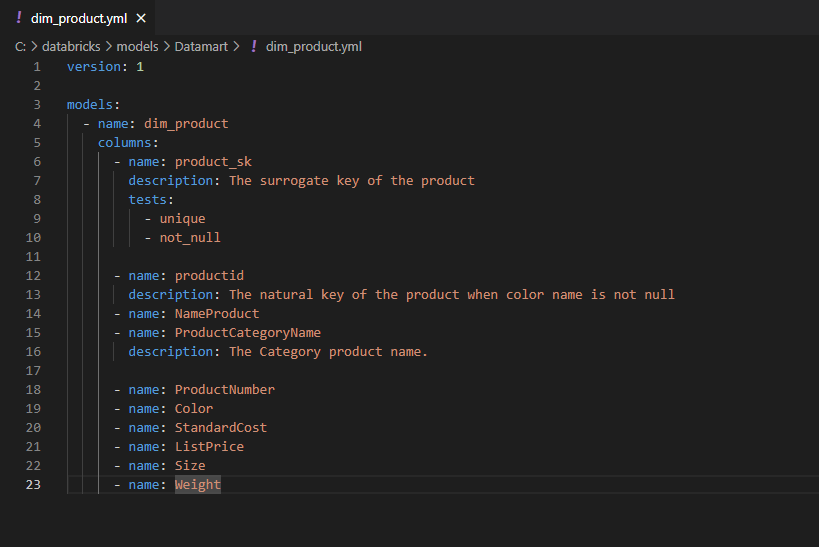
- yml: Il s’agit d’un fichier de configuration YAML utilisé par dbt pour définir les propriétés du projet. Il est utilisé pour définir des paramètres tels que le nom du projet, les informations d’identification pour se connecter à un entrepôt de données, les dépendances de projet et les plugins dbt à utiliser.
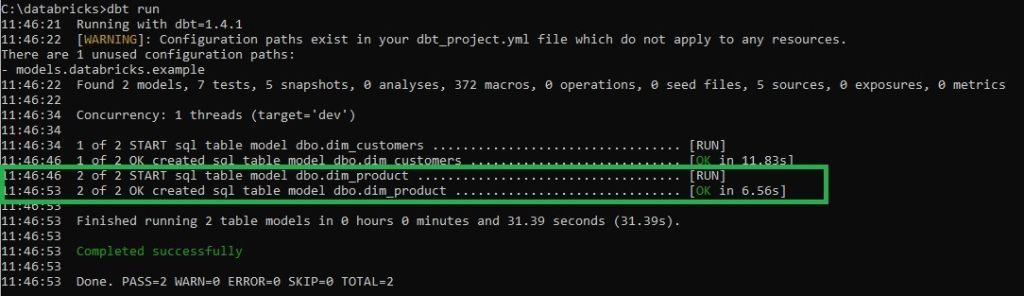
dbt run
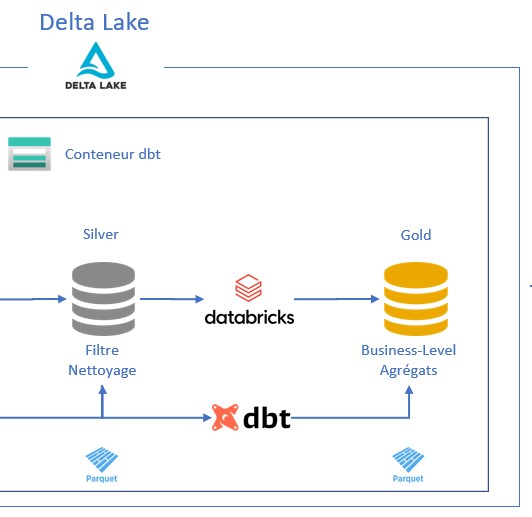
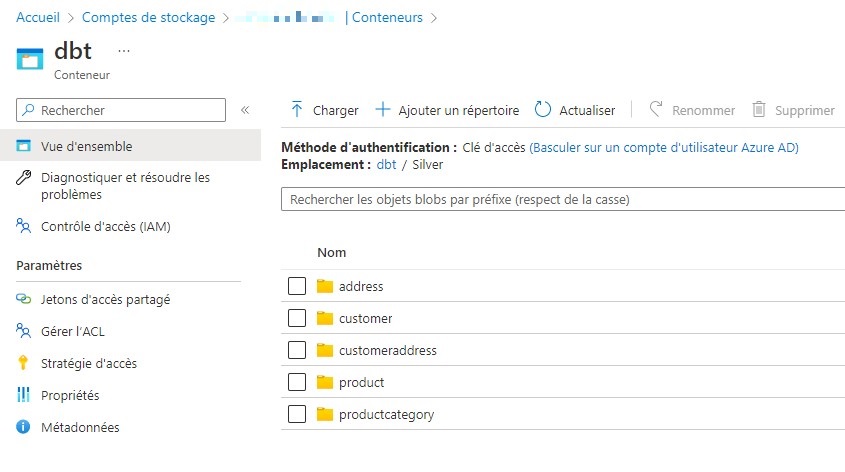
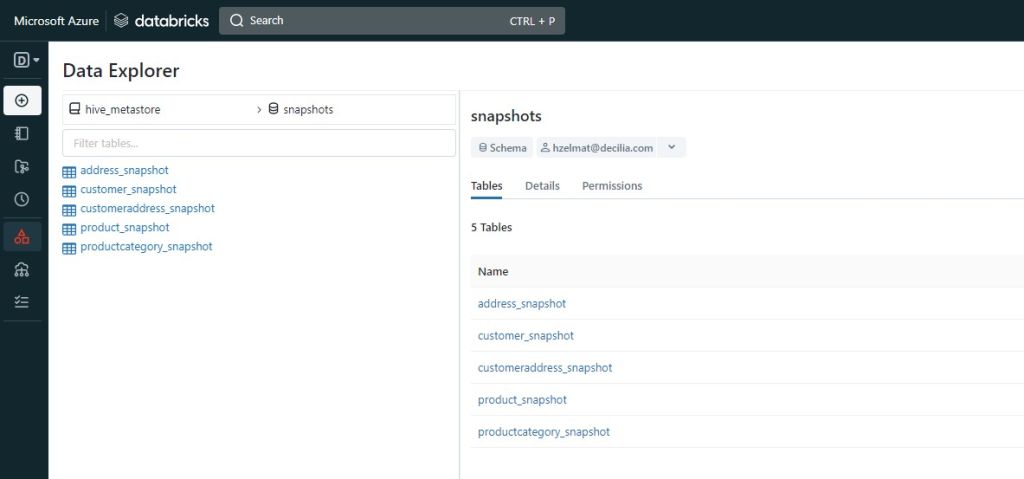
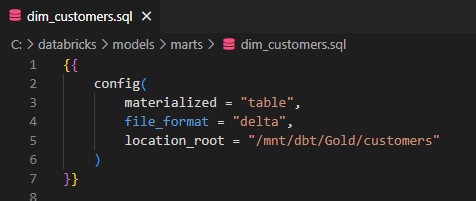
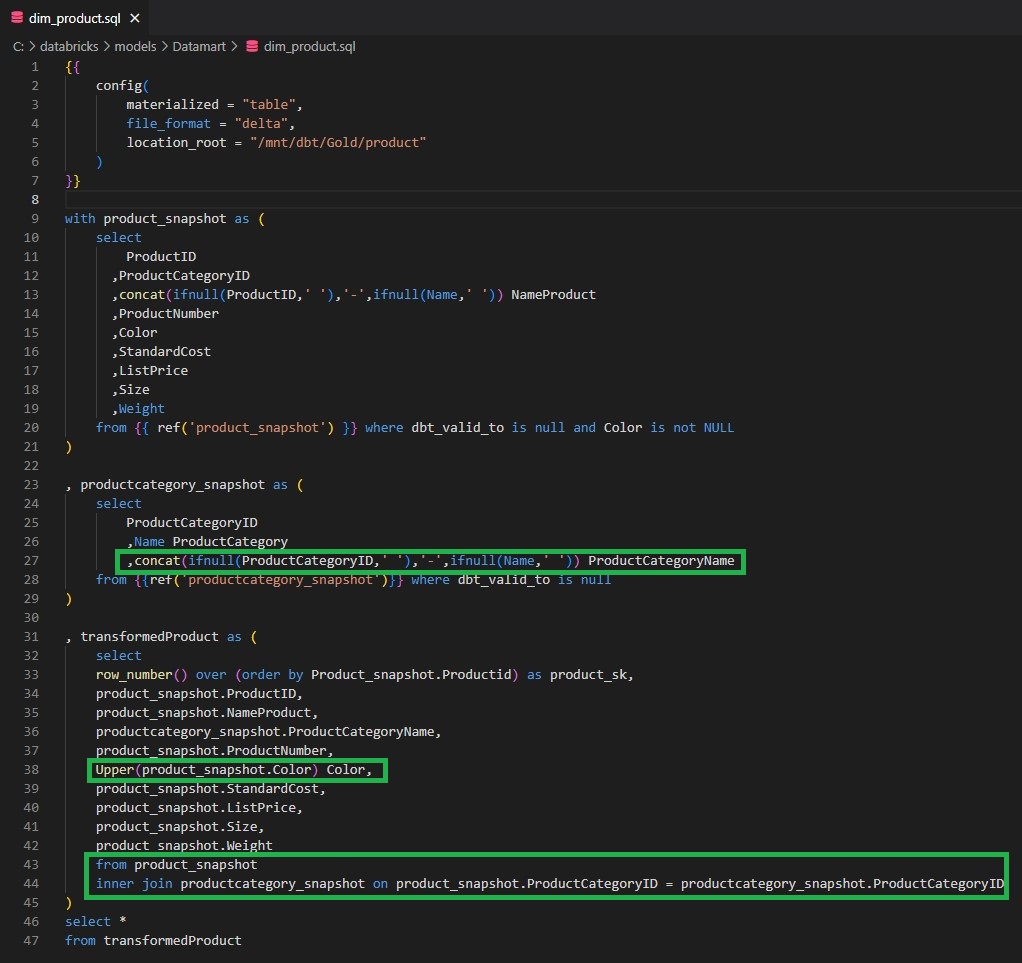
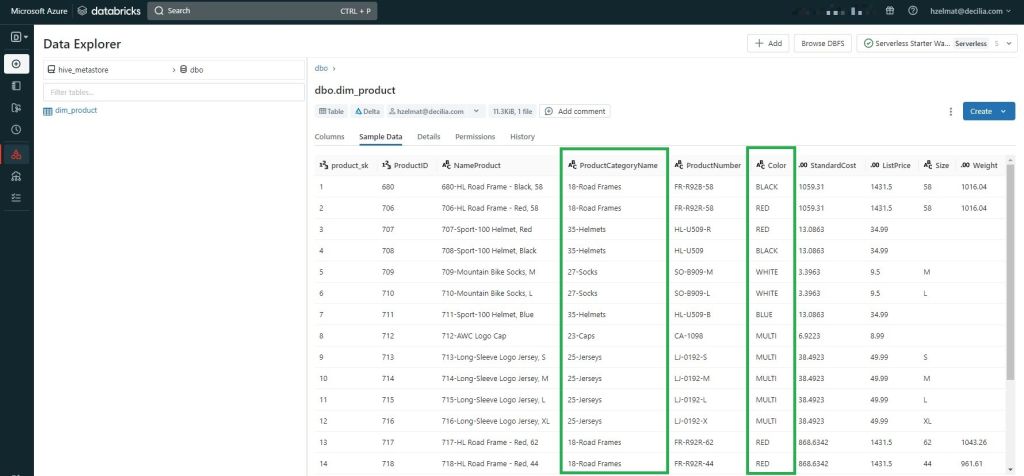
- Le contenu de la colonne « Color» est mis en majuscule.
- Deux colonnes « ProductCategoryID» et « Name » sont concaténées pour créer une unique colonne « ProductCategoryName ».
- Une jointure est réalisée entre les jeux de données « productcategory_snapshot » et « product_snapshot » pour récupérer la colonne concaténée « ProductCategoryName ».