Khaled FEHRI, Data Engineer
Dans un monde professionnel cherchant continuellement à optimiser la productivité et accroître le chiffre d’affaires, valoriser les données de l’entreprise et utiliser des outils analytiques performants tout en diminuant les coûts est devenu essentiel.
Pour ce faire, de nombreuses solutions et outils data sont disponibles, que ce soit pour le stockage de fichiers, le traitement des données ou leur restitution sous forme de visuels interactifs.
Certaines solutions peuvent être complexes et fastidieuses à mettre en place. C’est pourquoi il est important de les sélectionner judicieusement en fonction de ses besoins afin d’en tirer un maximum de bénéfices.
Dans cet article, nous allons étudier une solution dédiée à l’exploitation des données d’un data lake. Celle-ci a pour avantage d’être facile à mettre en place, économique, évolutive et performante lors de l’exécution de requêtes sur des datasets volumineux. Elle s’articule autour des outils Power BI et Azure Synapse Analytics Serverless SQL Pool.
Power BI est un outil complet de construction de tableaux de bord interactif. Azure Synapse Analytics Serverless SQL Pool offre quant à lui des capacités d’analyse de données avancées, incluant le traitement parallèle, la mise en cache des données et l’exécution de requêtes SQL sur des données non structurées.
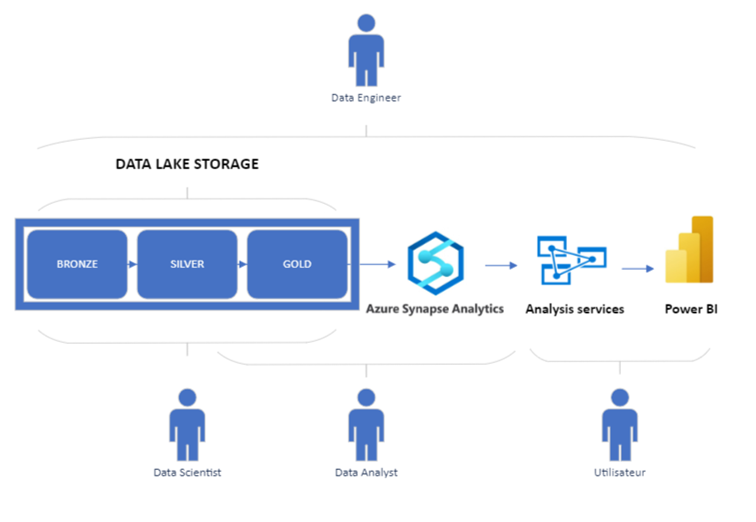
La mise en place de la solution Azure Synapse Analytics Serverless couplé à Power BI nécessite des compétences diverses. Afin de mener à bien son implémentation dans votre organisation, il est important d’identifier les différents profils qui seront amenés à intervenir, ainsi que leur rôle associé.
Selon la structure de chaque entreprise, les rôles listés ci-dessous peuvent différer légèrement :
- Data Engineer : Intervient sur toute la chaine d’alimentation en chargeant et transformant les données issues de différentes sources (BDD transactionnelle, streaming…), avant de les stocker dans un Data Lake ou Lakehouse. Il peut également travailler sur l’exposition des données analytiques via des cubes SSAS ou modèles Power BI.
- Data Scientist : A pour mission l’analyse et l’exploitation de l’ensemble des données de l’entreprise en développant des modèles prédictifs et aidant à la prise de décision par la conception d’algorithmes.
- Data Analyst : A pour mission l’exploitation et l’interprétation des données en développant de rapports et dashbords visant à extraire des insights métiers pertinents.
- Business User : Accède et consomme les données de son périmètre, mises à disposition sous forme de cube SSAS, modèles et/ou rapports Power BI.
POWER BI
De manière autonome, Power BI propose de nombreux connecteurs pour accéder à diverses sources de données, y compris une connexion directe à Azure Data Lake Gen2 (ADLS Gen2). Il permet également de traiter et d’analyser plusieurs types de fichiers. Une question se pose alors : pourquoi l’associer à Azure Synapse Analytics ?
Pour commencer, Power BI, lorsqu’il est connecté à Azure Data Lake Gen2, se limite au mode Import de données. Cela impose des limites sur la taille des datasets et charrie de nombreuses contraintes pour le traitement de données récentes ou quasi-instantanées. Par ailleurs, une solution pour contourner ces restrictions est d’opter pour Power BI Premium Capacity, qui, bien que coûteuse, n’est pas idéale pour gérer d’importants volumes de données, en particulier ceux provenant de fichiers parquet.
C’est pour cela qu’il est judicieux d’intégrer Azure Synapse Analytics à notre architecture Data, cette ressource, parfaitement intégrée à Azure Data Lake Store Gen2, offrant d’excellentes performances et des fonctionnalités Big Data adaptées aux solutions Analytics.
En somme, l’utilisation d’un outil comme Azure Synapse Analytics est vivement recommandée si les données stockées dans votre data lake dépassent 1GB ou si un rafraîchissement fréquent des données est nécessaire.
Pour plus d’informations sur les limites, consultez l’article : Gérer le stockage de données dans vos espaces de travail – Power BI | Microsoft Learn
Azure Synapse Analytics est un service d’analyse qui réunit l’entreposage de données d’entreprise et l’analyse Big Data.
Il propose un espace de travail doté de différentes fonctionnalités pour analyser les données issues de différents data stores. Chaque espace de travail nécessite un compte de stockage Data Lake Storage afin de stocker les informations systèmes et métadonnées requises pour le fonctionnement de Synapse. Grâce aux services liés (Linked services) et à une vaste gamme de connexions à divers entrepôts, Synapse fait le lien entre les divers services et structures de données.
Synapse apporte de nombreuses solutions et capacités d’analyse basées sur Apache Spark et SQL. L’approche d’analyse SQL est fournie par les ressources principales appelées SQL Pools qui se décline en deux modèles de consommation : Dédier et Sans serveur (Serverless).
Ces deux pools répondent à différents besoins en matière de traitement des données : le pool serverless est principalement utilisé pour l’exploration des données et l’exécution de requêtes ad-hoc, tandis que les pools SQL dédiés constituent la base de l’entreposage de données. La tarification est également différente pour ces deux approches : les seconds sont facturés en fonction du niveau de consommation provisionné, tandis que les premiers sont facturés en fonction des données traitées.
Les avantages d’utilisation d’Azure Synapse serverless SQL pools sont :
- Directement disponible pour interroger les données dans un datalake, et ce dès la création de l’espace de travail.
- Pas d’infrastructure à configurer ni de clusters à entretenir.
- Pas de pipeline à créer.
- Pas besoin de provisionner de Spark pools ou Dedicated SQL pools.

Azure Synapse serverless SQL pools prend en charge plusieurs formats de fichiers depuis un Data Lake, à savoir du :

SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://decilia.dfs.core.windows.net/nyctaxi/2023/01/yellow_tripdata_2023-01.parquet',
FORMAT = 'PARQUET'
) AS [result]
Dans l’exemple ci-dessus, T-SQL est utilisé pour faire un SELECT sur toutes les données contenues dans le fichier parquet spécifié dans le OPENROWSET.

Afin d’illustrer la création d’objets SQL depuis Azure Synapse Analytics Serverless Pool, nous utilisons des fichiers parquets des taxis de la ville de New-York. Ces fichiers sont stockés dans un compte de stockage ADLS Gen2 suivant l’arborescence « nyctaxi/année/mois ».
- Nous commençons par créer notre base de données virtuelle :
CREATE DATABASE DemoDB
2. Nous créons ensuite un format de fichier externe pour les fichiers parquets afin de pouvoir les explorer :
IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'SynapseParquetFormat')
CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat]
WITH ( FORMAT_TYPE = PARQUET)
3. Nous créons ensuite notre source de données externe pointant sur notre data lake :
IF NOT EXISTS (SELECT * FROM sys.external_data_sources WHERE name = 'DemoLake')
CREATE EXTERNAL DATA SOURCE [DemoLake]
WITH (
LOCATION = 'abfss://nyctaxi@Decilia.dfs.core.windows.net'
)
GO
4. Nous créons une table externe nommée All_2023_NY_TAXI.
NB : La clause WITH, qui spécifie l’emplacement relatif des fichiers parquet, prend également en paramètre :
- la source de données créée précédemment
- le format de fichier SynapseParquetFormat tout juste créé
CREATE EXTERNAL TABLE LDW.All_2023_NY_TAXI (
[VendorID] bigint,
[tpep_pickup_datetime] datetime2(7),
[tpep_dropoff_datetime] datetime2(7),
[passenger_count] float,
[trip_distance] float,
[RatecodeID] float,
[store_and_fwd_flag] nvarchar(4000),
[PULocationID] bigint,
[DOLocationID] bigint,
[payment_type] bigint,
[fare_amount] float,
[extra] float,
[mta_tax] float,
[tip_amount] float,
[tolls_amount] float,
[improvement_surcharge] float,
[total_amount] float,
[congestion_surcharge] float,
[airport_fee] float
)
WITH (
LOCATION = '2023/*/*.parquet',
DATA_SOURCE = [DemoLake],
FILE_FORMAT = [SynapseParquetFormat]
)
GO
Par le biais de cette table, nous avons ainsi accès à l’ensemble des données des fichiers de 2023 présents dans l’arborescence de notre compte de stockage.
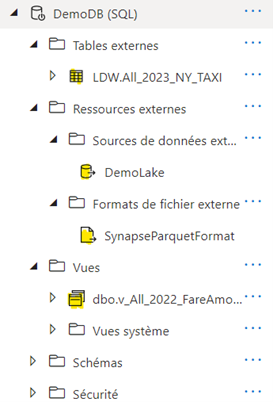
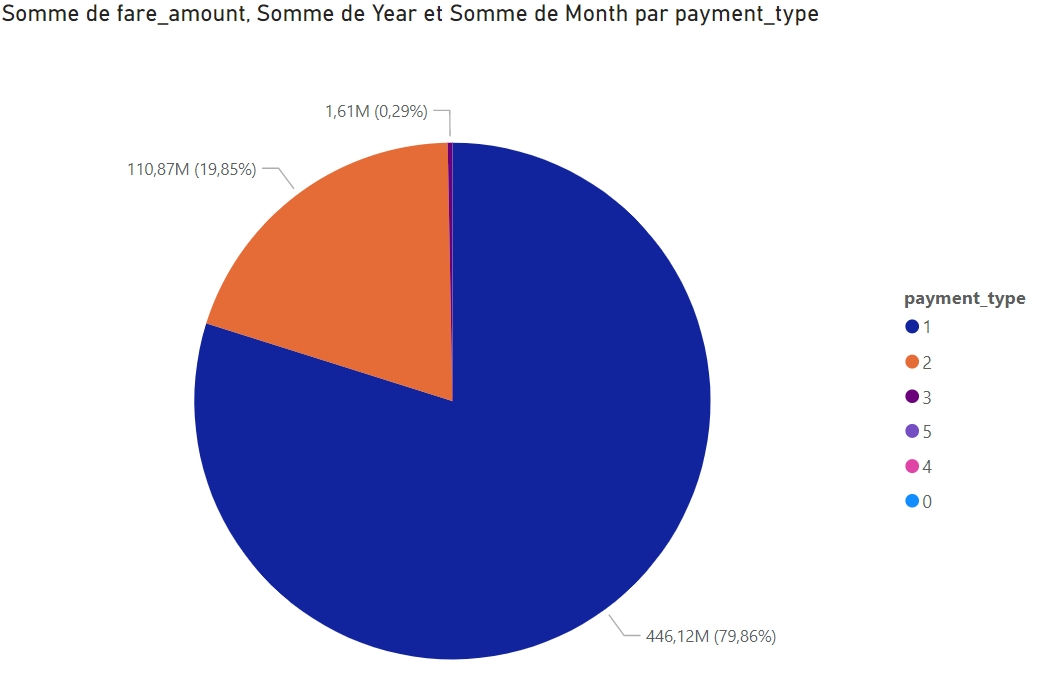
5. Pour terminer, nous pouvons créer des vues. Dans cet exemple, nous calculons la somme des tarifs par type de paiement pour l’année 2022 :
CREATE VIEW [dbo].[v_All_2022_FareAmount]
AS
SELECT
YEAR(tpep_pickup_datetime) Year,
MONTH(tpep_pickup_datetime) Month,
payment_type,
SUM(fare_amount) AS fare_amount
FROM
OPENROWSET(
BULK '*/*/*.parquet',
DATA_SOURCE = 'DemoLake',
FORMAT='PARQUET'
) nyc
WHERE
nyc.filepath(1) = 2022
AND tpep_pickup_datetime BETWEEN CAST('1/1/2022' AS datetime) AND CAST('12/31/2022' AS datetime)
GROUP BY
YEAR(tpep_pickup_datetime),
MONTH(tpep_pickup_datetime),
payment_type

La base de données contient ainsi les objets suivants :
- Table Externe : All_2023_NY_TAXI.
- Data source externe : DemoLake
- Formats de fichiers externes : SynapseParquetFormat
- Vue : v_All_2022_FareAmount
Azure Synapse Analytics SQL Serverless permet de requeter et d’analyser les données stockées dans un datalake. En le combinant à Power BI, il est possible d’en tirer plusieurs avantages :
- Intégration native : Azure Synapse Analytics SQL Serverless s’intègre parfaitement avec Power BI en proposant un point de terminaison pour se connecter comme n’importe quelle base de données. Il offre ainsi les mêmes avantages que les bases SQL Server, à savoir les modes de connexion Direct Query ou Import, ou encore la gestion intégrée de la sécurité.

- Données à jour en temps réel(Mode Direct Query) : Il n’est pas nécessaire de rafraichir les données car les rapports et tableaux de bord Power BI refleteront toujours les données les plus récentes du datalake.
- Meilleures performances : Azure Synapse Analytics SQL Serverless est une solution polyvalente, compatible avec plusieurs types de fichiers. Néanmoins, l’utilisation de fichiers parquet est recommandée dans un souci de performance. Aussi, en profitant du concept de « query folding », le moteur Power Query de Power BI va pouvoir s’affranchir de certaines tâches en déléguant différents traitements à la source de données (Azure Synapse Analytics SQL Serverless).
- Système évolutif: Synapse Analytics permet d’adapter les ressources disponibles en fonction du besoin, de manière à gérer les pics de charges.
- Coûts à l’utilisation : Azure Synapse Analytics SQL Serverless ne facture que les ressources utilisées réellement. Le serveur reste disponible, à tout moment, sans coûts supplémentaires tant que celui-ci n’est pas utilisé.
- Optimisation des coûts (Mode Import) : En passant par le mode import, il est possible de charger les données d’Azure Synapse Analytics SQL Serverless dans Power BI Premium. Ainsi, les coûts d’usage n’interviennent qu’au rafraichissement du modèle Power BI, et non lors de la manipulation des données par les utilisateurs.
- Pas d’infrastructure à gérer : Azure Synapse Analytics SQL Serverless permet de se focaliser entièrement sur l’analyse des données sans la nécessité la gérer l’infrastructure ou les clusters.
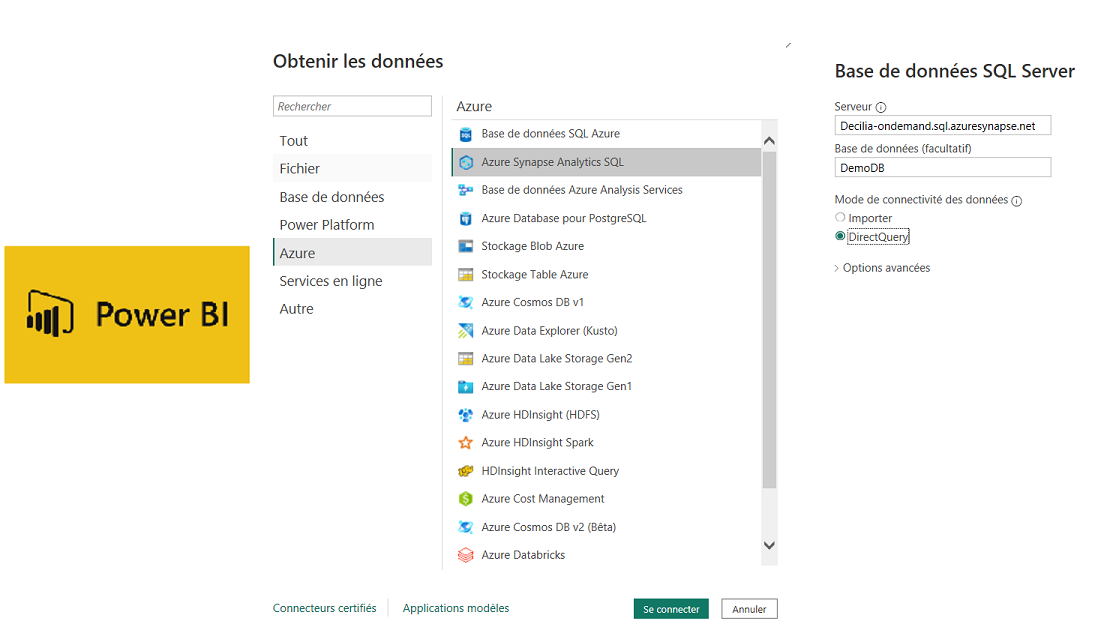
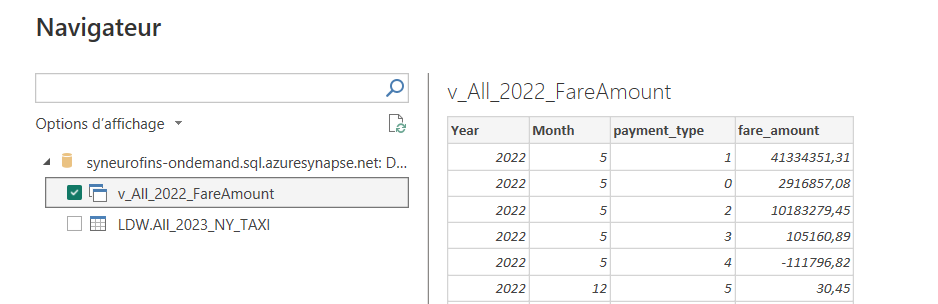
Ci-dessous un exemple de connexion à Serverless SQL via Power BI :
En résumé, combiner l’utilisation de Power BI et d’Azure Synapse Analytics SQL Serverless est une solution à envisager lorsque vous avez besoin d’une analyse de données cloud flexible, évolutive et économique, en particulier pour l’analyse ad hoc de données stockées dans des lakehouses Azure. Cette solution convient aussi aux entreprises souhaitant maîtriser leurs coûts tout en bénéficiant d’une solution puissante et totalement intégrée à leur environnement Azure.