Rafik BELLAHSENE, Data Architect
Dans un précédent article, nous avons plongé dans le monde de Delta Live Tables de Databricks, en explorant ses fonctionnalités et ses limites d’utilisation. Nous avons découvert à quel point cet outil était puissant pour la gestion de données à grande échelle.
Aujourd’hui, nous allons poursuivre cette exploration en décrivant comment concevoir et développer des processus ETL puissants et évolutifs grâce à Delta Live Tables.
Si vous avez suivi mon précédent article, vous savez déjà que Delta Live Tables est conçu pour simplifier la gestion de vos flux de données, tout en offrant des fonctionnalités robustes pour garantir leur qualité et fiabilité.
Dans cette suite, nous explorerons comment extraire des données à partir de diverses sources, les transformer, puis les charger dans votre Delta Lakehouse.
Dans les lignes qui suivent, nous allons voir comment Delta Live Tables peut être utilisé pour mettre en place un Delta Lakehouse de manière efficiente.
Description de l'architecture Medaillon
Pour rappel, l’architecture Medaillon est un paradigme d’architecture de données permettant de segmenter de manière logique les données au sein d’un Lakehouse. Il permet d’améliorer la structure et la qualité des données au fur et à mesure qu’elles traversent les différentes couches de l’architecture Bronze, Silver et Gold
Source : Databricks Documentation
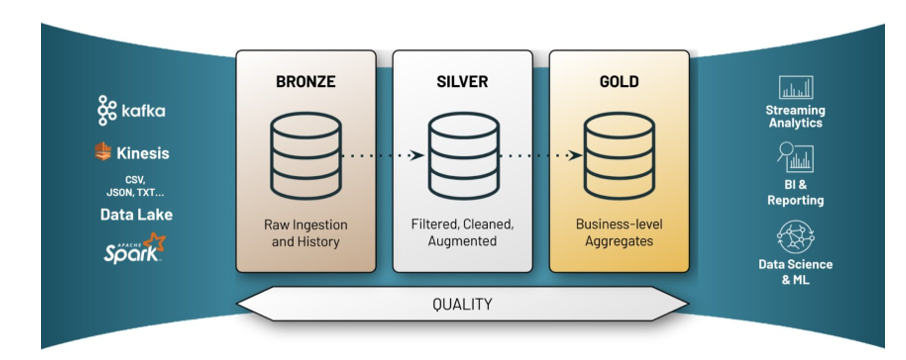
Explication des couches de données
Couche Bronze : C’est la couche de stockage des données brutes permettant l’archivage historicisée de la source, la data lineage et le traitement des données sans relecture du système source.
Couche Silver : Elle intègre, nettoie et harmonise les données de la couche Bronze pour créer une vue d’entreprise consolidée. Elle permet aux data scientists et data engineers d’explorer et d’analyser l’ensemble des données via une modélisation de type 3NF.
Couche Gold : La couche Gold du lakehouse contient des datamarts dédiés à des projets spécifiques, qui permettent aux data analysts de créer des rapports et dashboards à partir de modèles de données dénormalisés. Elle intègre les règles métier nécessaires pour effectuer des analyses avancées à grande échelle.
Développement du pipeline Delta Live Tables (DLT)
Maintenant que nous avons détaillé les concepts derrières la conception fonctionnelle d’un Delta Lakehouse, nous allons mettre en pratique ces connaissances ETL à travers un pipeline DLT.
Prérequis
- Workspace Databricks
- Cluster Databricks : Runtime DBR 12.2 LTS en Single Node
- Notions en Python
- Compte de stockage Azure, avec un mount point configuré
Datasets
Pour ce tutoriel, nous allons utiliser les jeux de données de l’API OpenFlights.
Description du dataset
Le jeu de données collecté est composé de plusieurs fichiers :
Nom du fichier | Format | Description | Structure |
Airports | CSV | Référentiel des aéroports du monde | Airport ID : Int Name : String City : String Country : String IATA : String ICAO : String Latitude : Float Longitude : Float Altitude : Float Timezone : Float DST : String Tz database time zone : String Type : String Source : String |
Airlines | CSV | Référentiel des compagnies aériennes du monde | Airline ID : Int Name : String Alias : String IATA : String ICAO : String Callsign : String Country : String Active : String |
Countries | CSV | Référentiel des pays | Name : String Iso_code : String Dafif_code : String |
Routes | CSV | Référentiel des itinéraires de vols | Airline : String Airline ID : Int Source airport : String Source airport ID : Int Destination airport : String Destination airport ID : Int Codeshare : String Stops : Int Equipment : String |
Modélisation des couches de données du Delta Lakehouse
Notre Delta Lakehouse se compose des 4 couches suivantes :
- Couche Raw : Zone temporaire de dépôt des fichiers bruts.
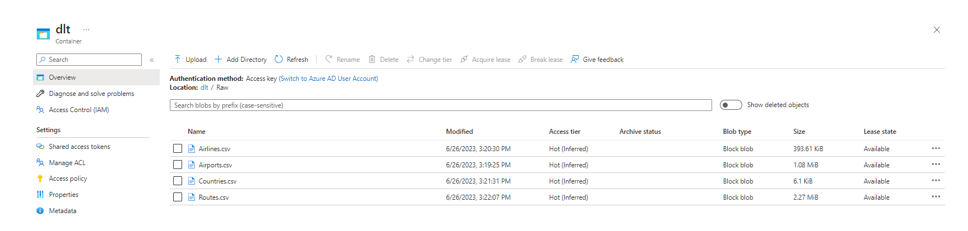
- Couche Bronze : Zone d’acquisition et d’historicisation des fichiers bruts. Elle est modélisée ainsi : ObjetSource/Fichier_delta
Chaque entité source est modélisée par un fichier Delta auquel sont rajoutées des métadonnées correspondant :
- A la date d’ajout dans la couche bronze
- Au libellé du fichier d’origine
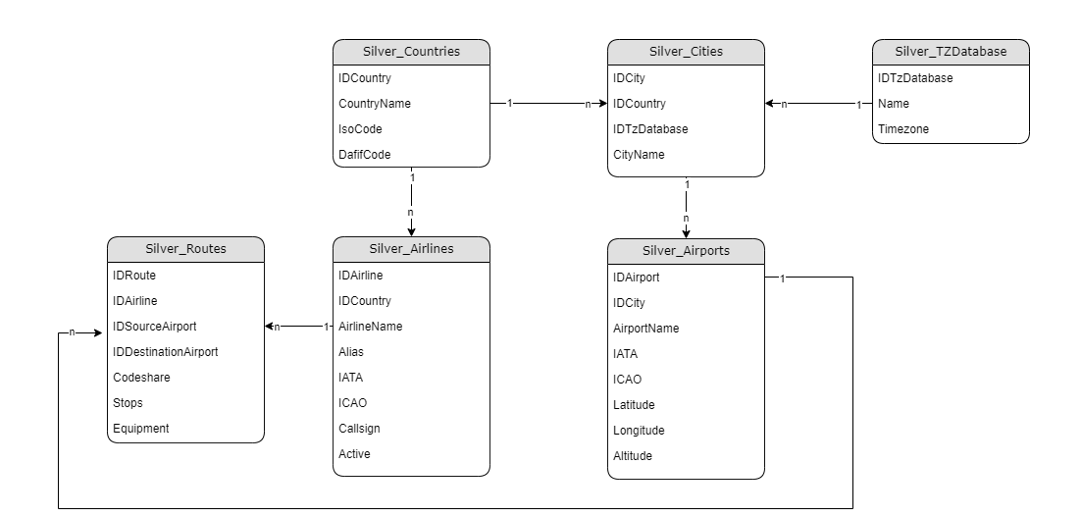
- Couche Silver : Modèle de données en 3ème forme normale, que l’on pourrait rapprocher d’un Data Warehouse. (C.f figure ci-dessous)
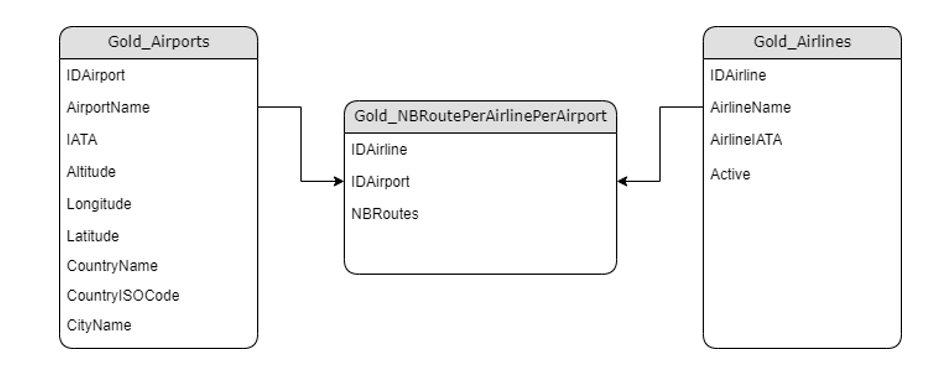
- Couche Gold : Modèle dénormalisé (en étoile) et agrégé des données, que l’on pourrait rapprocher d’un Datamart. Elle est composée de 2 dimensions et d’une table de faits.
Dans notre cas, on souhaiterait avoir le top 10 des compagnies opérant le plus de vols par aéroport.
Mise en place du pipeline Delta Live Tables
Avant de commencer, rendez-vous dans votre Workspace Databricks, au sein de la section Workspace/Users, puis cliquez sur Add Notebook
Une fois créé, définissez le langage par défaut du notebook. Dans notre cas, ça sera Python

Nous sommes à présent prêts pour la déclaration de nos diverses couches de données au sein du notebook créé.
Couche Bronze
import dlt
from datetime import datetime
from pyspark.sql.functions import lit,col,upper, sha2, concat, trim, regexp_replace,length,when,round,expr,desc, input_file_name,expr
def IngestRawFileToBronze(fileName):
@dlt.table(name="bronze_python_{}".format(fileName.lower()),
comment="Bronze Table for {}".format(fileName),
table_properties={"quality" : "bronze"},
path="/mnt/delta_live/Bronze/{}".format(fileName)
)
def table_raw():
# Infer Schema
schema = spark.read.option("inferSchema",True).csv("/mnt/delta_live/Raw/{}/*.csv".format(fileName),sep=',',header=True).schema
# Function that reads the raw CSV File and creates streaming table in Append mode
return spark.readStream.schema(schema).format("cloudFiles")\
.option("cloudFiles.format", "csv").\
.option("inferSchema", "true").\
load("/mnt/delta_live/Raw/{}/*.csv".format(fileName),sep=',',header=True)\
.withColumn("DAT_TECH_INSERT",lit(datetime.utcnow()))\
.withColumn("TXT_FILENAME",input_file_name())
Dans le code ci-avant, je commence par définir la fonction IngestRawFileToBronze(fileName) qui a pour but d’ingérer les fichiers CSV de la couche « Raw » vers la couche « Bronze ».
Cette opération est réalisée en utilisant Spark Structured Streaming pour lire les fichiers CSV en continu à partir de la source de données spécifiée, tout en inférant automatiquement le schéma des fichiers.
Une particularité importante à noter est l’utilisation de l’instruction .format(« cloudFiles »).option(« cloudFiles.format », « csv »). Celle-ci indique que nous faisons appel à l’Auto Loader de Databricks.
Qu’est-ce que Databricks Auto Loader ?
L’Auto Loader de Databricks est une fonctionnalité qui permet une ingestion rapide de données à partir de comptes de stockage Azure, AWS S3 ou GCP. Il repose sur le traitement structuré en continu (Structured Streaming) et utilise des points de contrôle (checkpoints) pour traiter immédiatement les fichiers dès qu’ils apparaissent dans un répertoire prédéfini. Il détecte automatiquement l’arrivée de nouveaux fichiers dans ce répertoire de données, ce qui facilite le chargement incrémentiel des nouvelles données. Cette fonctionnalité est rendue possible grâce à l’utilisation de fichiers checkpoints pour suivre et gérer le traitement des fichiers source.
Quel est le rôle du décorateur @dlt.table ?
Il permet de déclarer une Delta Live Table -Streaming ou Vue Matérialisée (Pour plus de détails, se référer à mon précèdent article disponible ici).
Ce décorateur accepte plusieurs paramètres facultatifs, dont les principaux sont :
- Name : Libellé de la table. Si ce nom n’est pas défini, le nom de la fonction est utilisé comme nom de la table.
- Comment : Description de la table.
- Table_properties : Liste des propriétés de la table. (Listes exhaustives disponibles ici : lien1, lien2)
- Path : Emplacement de stockage pour les données de la table. S’il n’est pas défini, le système utilise par défaut l’emplacement de stockage du pipeline.
Dans notre cas, il est important de noter que les tables créées dans la couche Bronze sont du type « Streaming Table ». Cette classification découle du fait que la fonction table_raw() renvoie un DataFrame Spark de type Structured Streaming. Par conséquent, les tables sont en « append-only ».
Couche SILVER
Ici, nous allons introduire la déclaration des tables au sein de notre couche Silver.
Ces tables sont représentées sous forme de tables de streaming de type SCD1 (Slowly Changing Dimension 1) en mode CDC (Change Data Capture).
Prenons un exemple concret avec la table « Country » qui est définie dans le script suivant :
#######################################################################################################
### Country Silver
#######################################################################################################
@dlt.table(name="countries_silver_tmp")
@dlt.expect_or_drop("DROP NULL IDS", "IDCountry IS NOT NULL")
def countries_silver_tmp():
return (
spark.readStream.option("skipChangeCommits", "true").table("LIVE.bronze_python_countries").select(
sha2(trim(upper(col("Name"))),256).alias("IDCountry"),
trim(upper(col("Name"))).alias("CountryName"),
col("Iso_code").alias("IsoCode"),
col("Dafif_code").alias("DafifCode"),
col("DAT_TECH_INSERT").alias("DAT_INSERT")
)\
.distinct()
)
dlt.create_target_table(name="Country",
path="/mnt/delta_live/Silver/Country",
)
dlt.apply_changes(
target = "Country",
source = "countries_silver_tmp",
keys = ["IDCountry"], #Primary key to match the rows to upsert/delete
sequence_by = col("DAT_INSERT"), #deduplicate by operation date getting the most recent value
stored_as_scd_type = 1
)
Dans ce code, j’ai spécifié plusieurs paramètres que nous allons maintenant examiner en détail :
- @dlt.table(name= »countries_silver_tmp ») : Libellé de la table source sur lequel est appliqué le CDC.
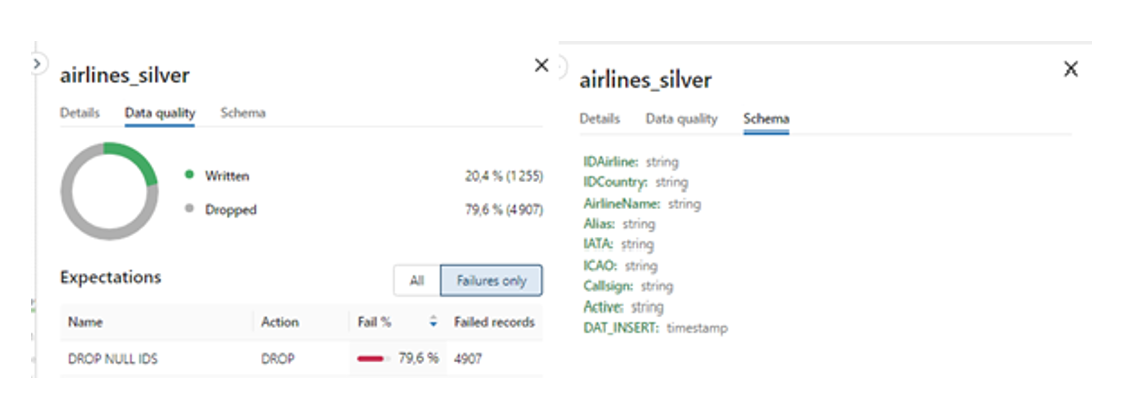
- @dlt.expect_or_drop(« DROP NULL IDS », « IDCountry IS NOT NULL ») : Contrôles d’intégrité des données insérées en Silver.
Dans notre cas, toutes les lignes pour lesquelles IDCountry est null seront supprimées.
- readStream.option(« skipChangeCommits », »true »).table(« LIVE.bronze_python_countries »):
- skipChangeCommits: permet de choisir d’ignorer ou non les modifications antérieures des données.
En configurant skipChangeCommits sur « true », vous ne considérez que l’état actuel des données, sans vous préoccuper de leur historique de changements. Cela est particulièrement utile pour les analyses qui nécessitent uniquement les informations les plus récentes, sans tenir compte des modifications passées. (c.f documentation)
- LIVE. : Permet d’appeler une table définie au sein du même pipeline Delta Live Table
- dlt.create_target_table(name= »Country »,path= »/mnt/delta_live/Silver/Country”): Table de destination (table Silver finale) qui sera mise à jour (UPSERT car SCD 1)) à partir de la table source défini avec le décorateur @dlt.table.
Le nom de la table est « Country » et le chemin de stockage des données de la table est « /mnt/delta_live/Silver/Country »
- dlt.apply_changes( target = « Country », #Table de destination
source = « countries_silver_tmp », #Table source
keys = [« IDCountry »], #Clé primaire pour faire correspondre les lignes à insérer/supprimer ou mettre à jour.
sequence_by = col(« DAT_INSERT »), #Supprimer les doublons en fonction de la date de l’opération en obtenant la valeur la plus récente.
stored_as_scd_type = 1 #Type d’historicisation (SCD1)
)
Les autres tables de la couche Silver suivent également la même logique d’alimentation.
COUCHE GOLD
Pour des questions de performances, j’utilise des vues matérialisées pour créer les tables de la couche Gold :
#######################################################################################################
### DIMENSION GOLD AIRPORTS
#######################################################################################################
@dlt.table(name="dim_airports_gold",
table_properties={"quality" : "gold"},
path="/mnt/delta_live/Gold/DIM_Airports")
def dim_airports_gold():
return dlt.read("Airport").drop("DAT_INSERT").join(dlt.read("City").select(col("IDCity").alias("ID_City"),
col("IDCountry").alias("ID_Country"),
"CityName"), how = 'left', on = expr("ID_City = IDCity"))\
.drop("IDCity")\
.join(dlt.read("Country").select("IDCountry",
"IsoCode",
"DafifCode",
"CountryName"), how = 'left', on = expr("IDCountry = ID_Country"))\
.drop("ID_Country","IDCountry","ID_City")
#######################################################################################################
### DIMENSION GOLD AIRLINES
#######################################################################################################
@dlt.table(name="dim_airlines_gold",
table_properties={"quality" : "gold"},
path="/mnt/delta_live/Gold/DIM_Airlines")
def dim_airlines_gold():
return dlt.read("Airline").select("IDAirline",
"AirlineName",
col("IATA").alias("AirlineIATA"),
"active")
#######################################################################################################
### TABLE D'AGREGAT GOLD NBROUTE_PER_AIRPORT_PER_AIRLINE
#######################################################################################################
@dlt.table(name="fct_nbroutesprairlineandairp_gold",
path="/mnt/delta_live/Gold/FCT_NB_RTE_PER_AIRPORT_AIRLINE")
def fct_nbroutesprairlineandairp_gold():
base = dlt.read("Route").select("IDAirline",
"IDSourceAirport",
"IDDestinationAirport")
# Utilisez la méthode selectExpr pour créer une colonne 'Type d'aéroport' qui contient soit 'Aéroport source' soit 'Aéroport de destination'
df = base.selectExpr("IDAirline", "stack(2, 'IDSourceAirport', IDSourceAirport, 'IDDestinationAirport', IDDestinationAirport) as (Type_d_aeroport, Aeroport)")
# Utilisez groupBy pour obtenir le nombre de vols par compagnie aérienne et par aéroport
nombre_de_vols_par_compagnie_aeroport = df.groupBy("IDAirline", "Aeroport").count()
return nombre_de_vols_par_compagnie_aeroport.withColumnRenamed("Aeroport", "IDAirport")
Dans ce script, j’ai spécifié les paramètres suivants :
- @dlt.table(name= » dim_airlines_gold « ) : Libellé de la dimension « Airlines » de la couche gold.
- read(« Airline ») : Fonction qui permet de lire une table définie dans le pipeline DLT.
Dans notre cas, la dimension Airline est une vue matérialisée qui se base sur la table Silver « Airline »
Configuration du pipeline Delta Live Tables
Une fois le flux ETL déclaré et développé, nous procédons à la configuration du pipeline DLT. Pour ce faire, cliquez sur la section « Delta Live Tables » du panneau latéral, puis sur « Create pipeline »
Pour la configuration du pipeline, il est demandé de renseigner un certain nombre de paramètres (Pour plus de détails, se référer à mon précèdent article).
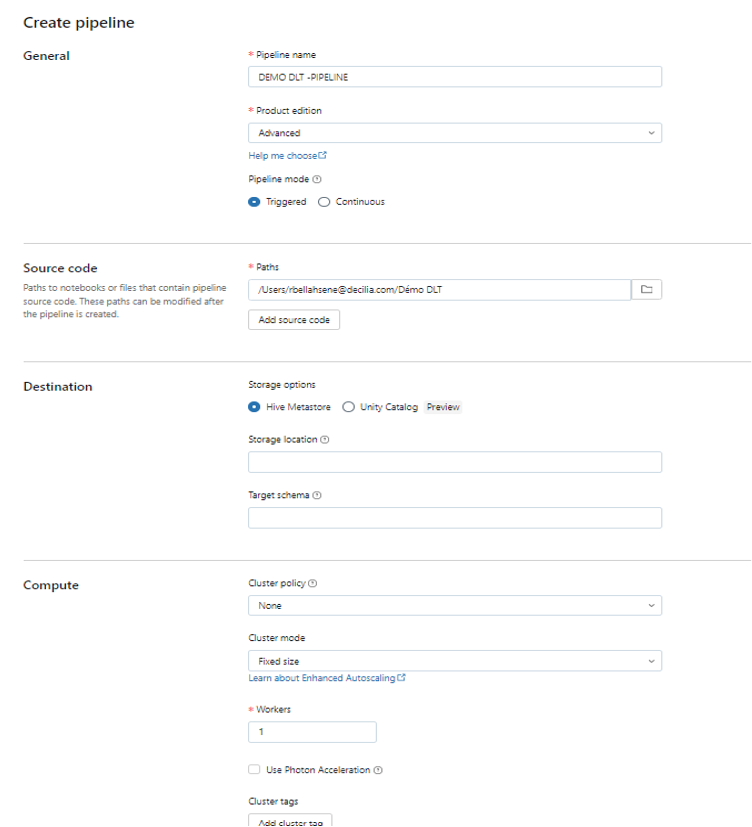
Dans ce contexte spécifique, j’utilise le Hive Metastore pour enregistrer les métadonnées associées aux tables générées dans le cadre du pipeline DLT.
Pour simplifier ce cas d’usage, je choisis de ne pas utiliser Unity Catalog, ce qui explique l’absence d’informations telles que le chemin de stockage des données (Storage Location) et la base de données dans laquelle nos données seront stockées (Target Schema).
Une fois le pipeline configuré, vous pourrez le lancer et observer le data lineage de votre flux ETL.
Data Lineage
Delta Live Table offre la possibilité de créer un graphe de visualisation (Data Lineage) de nos flux de données. Ce schéma résume l’itinéraire des données, depuis leur origine jusqu’à leur exposition finale.
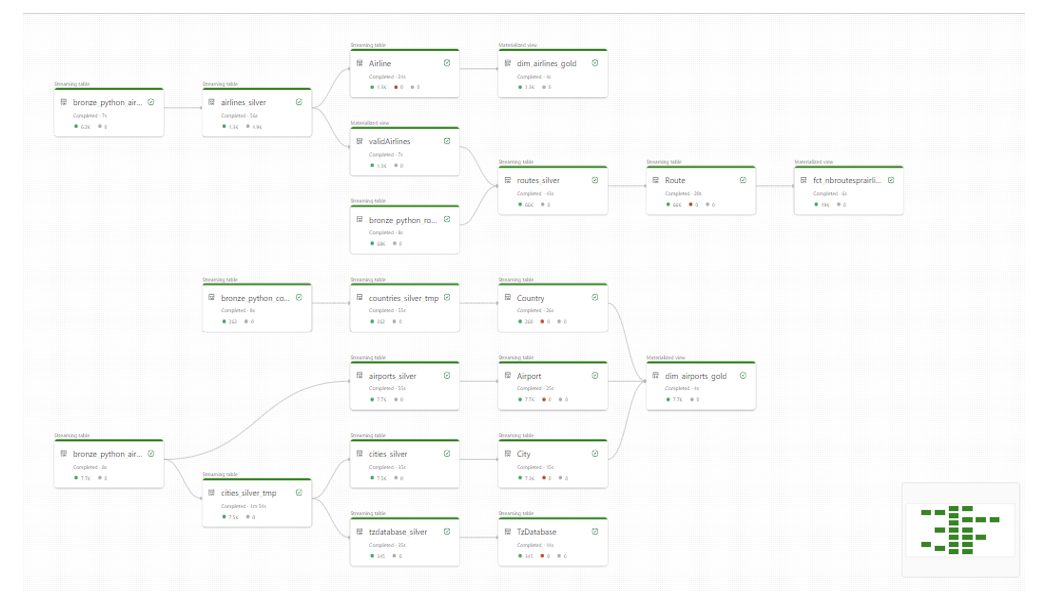
Concentrons-nous sur l’itinéraire des données du fichier source Airlines :
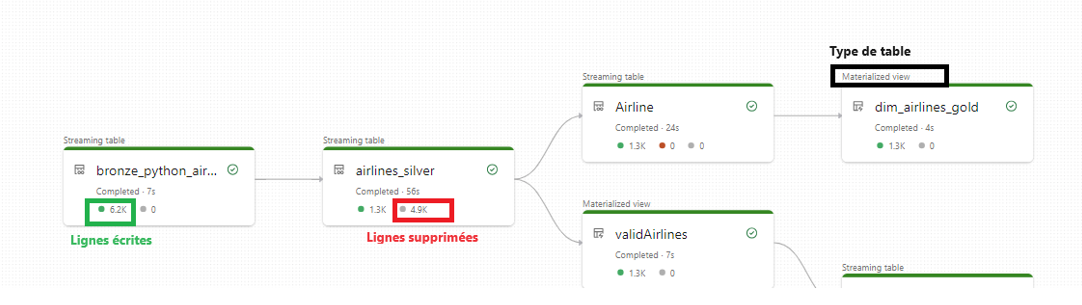
En plus de décrire les différentes étapes de transformations et stockages des données, le graphique nous apporte des informations complémentaires sous forme de métriques, notamment :
- Le décompte des lignes écrites pour chaque table
- Le décompte des lignes rejetées pour chaque table
- Le type attribué à chaque Delta Live Table
Lorsque je sélectionne une table dans le graphique, j’ai la possibilité d’examiner de manière plus approfondie les contrôles d’intégrité appliqués et les schémas associés à chacune d’elle.
Au travers de nos deux articles traitant de Delta Live Tables, nous avons eu l’opportunité de découvrir les fonctionnalités et spécificités de cet outil puissant. Ensemble, nous avons construit un pipeline DLT et illustré son application à travers un cas d’usage concret.
En conclusion, Delta Live Tables s’impose comme un outil formidable qui simplifie considérablement l’intégration de données à grande échelle dans un environnement Databricks. Son approche déclarative permet de créer des pipelines de données de manière efficace et fiable, ce qui en fait un atout précieux pour les projets de gestion et d’analyse de données complexes.