Samy ABTOUT, Data Engineer
Introduction
Dans un environnement cloud, il est essentiel de mettre en place une gestion efficace reposant sur une gouvernance des ressources, un suivi des flux de données et un pilotage minutieux des coûts, garantissant ainsi une optimisation opérationnelle et financière de la plateforme.
Les tables système Databricks constituent un atout majeur pour répondre à ce besoin. En centralisant les données opérationnelles et d’utilisation de votre metastore, elles offrent une observabilité historique complète et permettent de suivre de près les différents aspects de votre environnement Databricks.
Databricks génère automatiquement des métadonnées pour chaque opération effectuée dans la plateforme. Celles-ci sont stockées de manière centralisée dans des tables systèmes de votre metastore Databricks.
Présentation des tables systèmes
Les tables système sont des tables analytiques hébergées par Azure Databricks contenant les métadonnées opérationnelles de votre compte. Elles se trouvent dans le catalogue system et permettent un monitoring complet de :
- L’utilisation des services Databricks (SQL Warehouse, Unity Catalog, Notebook, Jobs, Delta Lives Tables etc..)
- La consommation des ressources avec le temps d’utilisation et la facturation associée
- Le Data lineage à la granularité tables ou colonnes
- Les tâches de maintenances lancées par Databricks
Actuellement, cinq bases de données sont disponibles dans le catalogue system :
- Access
- Audit: Contient les informations de tous les évènements liés au compte Databricks (connexions, exécutions de requêtes SQL, utilisation du Delta sharing, suppression d’un composant etc…). Il existe plus de 300 évènements.
- Column_lineage : Contient les informations de Data lineage à la granularité colonne
- Table_lineage : Contient les informations de Data lineage à la granularité table
- Billing
- List_prices : Contient les tarifs par DBU des différents types de compute par régions
- Usage : Contient les informations d’utilisation des computes en DBU du compte Databricks
- Compute
- Clusters : Contient l’historique des clusters créés dans le compte Databricks
- Node_types : Contient la liste des clusters Databricks avec leurs caractéristiques
- Warehouse_events : Contient l’historique des états des clusters SQL
- Marketplace
- Listing_access_events : Contient les informations des consommateurs de vos données présentes dans le Marketplace Databricks
- Listing_funnel_events : Contient les interactions des utilisateurs avec les produits ou services proposés sur le Marketplace Databricks
- Storage
Predictive_optimization_operations_history : Contient des informations sur les tâches de maintenance lancées par Databricks
Un monitoring complet de la plateforme de données dans Databricks est possible grâce aux bases de données systèmes Access et Billing. Contrairement aux fichiers de logs, les tables systèmes offrent une vue unifiée et facilement requêtable des métadonnées générées. Ceci permet de réaliser des diagnostiques rapides et des prises de décisions adéquates.
Mise en conformité
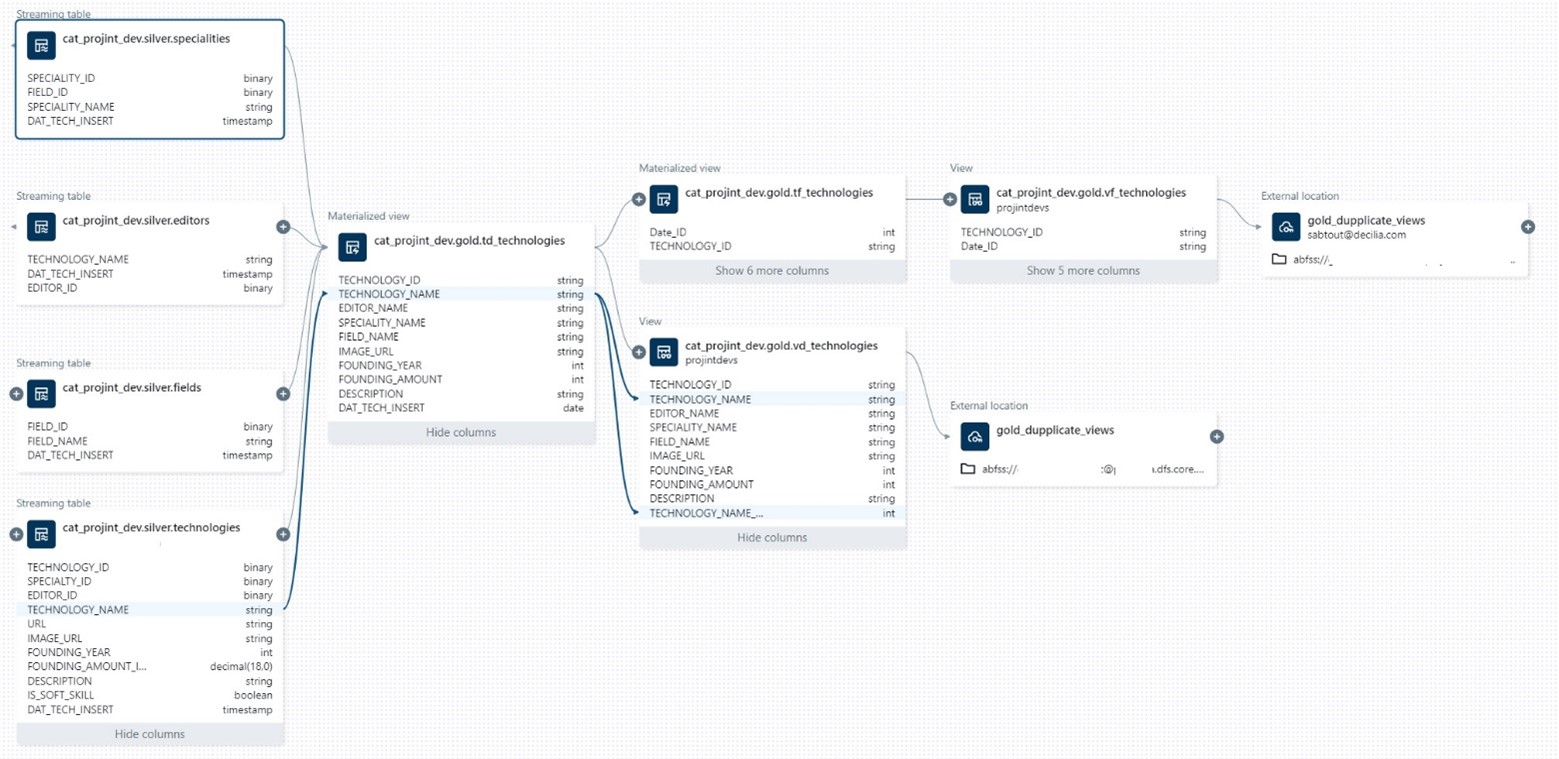
La traçabilité des données est facilitée grâce à la base de données système Access, permettant d’accéder au Data Lineage à la granularité colonne via les métadonnées présentes dans les tables Table_lineage et Column_lineage.
Cette granularité fine permet de visualiser le cycle de vie complet de la donnée, de sa source à son utilisation finale. Cette traçabilité est essentielle pour garantir la conformité aux réglementations telles que le RGPD, en permettant d’identifier et suivre l’origine des données.
Voici un exemple de l’interface graphique présentant le Data lineage d’une colonne :
Audit
La table audit fournit des informations sur les événements liés aux comptes Databricks, permettant ainsi une analyse approfondie de l’activité des utilisateurs. Cette table centralisée permet de réaliser différents audits :
- Suivi des droits d’accès utilisateurs : Identifiez précisément qui a accédé à quelles données et ressources, et quand.
- Analyse des performances des requêtes SQL : Optimisez les performances en analysant le temps d’exécution des requêtes et en identifiant les éventuels goulots d’étranglement.
- Suivi de la fréquence d’utilisation et des objets utilisés : Comprenez les habitudes d’utilisation des utilisateurs, les objets les plus sollicités et les tendances d’accès aux données.
Suivi de coût
La base de données système Billing dispose d’une table nommée Usage qui enregistre toutes les actions effectuées sur Databricks, ainsi que les DBU (Databricks Units) consommées et le type de compute utilisé.
De plus, la table List_prices catalogue le prix en dollars de chaque DBU en fonction de la date et du type de compute.
En combinant des requêtes sur ces deux tables, il est possible de reconstituer l’historique complet des actions menées sur Databricks, assorti du coût en dollars associé à chacune d’entre elles.
Voici un exemple de requête permettant d’analyser le coût par mois des différents types de compute par Workspace Databricks :
WITH CTE AS (
SELECT
u.account_id,
u.workspace_id,
u.sku_name,
u.cloud,
u.usage_date,
date_format(u.usage_date, 'yyyy-MM') as YearMonth,
u.usage_unit,
u.usage_quantity,
lp.pricing.default as price,
lp.pricing.default * u.usage_quantity as cost
FROM
system.billing.usage u
INNER JOIN system.billing.list_prices lp on u.cloud = lp.cloud and
u.sku_name = lp.sku_name and
u.usage_start_time >= lp.price_start_time and
(u.usage_end_time <= lp.price_end_time or lp.price_end_time is null)
)
SELECT
account_id,
workspace_id,
sku_name,
cloud,
YearMonth,
usage_unit,
sum(cost) as total_cost
FROM CTE
GROUP BY ALL
ORDER BY YearMonth
Le résultat de la requête peut être exploité via des outils de visualisation, tels que les tableaux de bord Databricks, afin d’obtenir un suivi clair, précis et personnalisé des coûts liés à l’utilisation de Databricks.
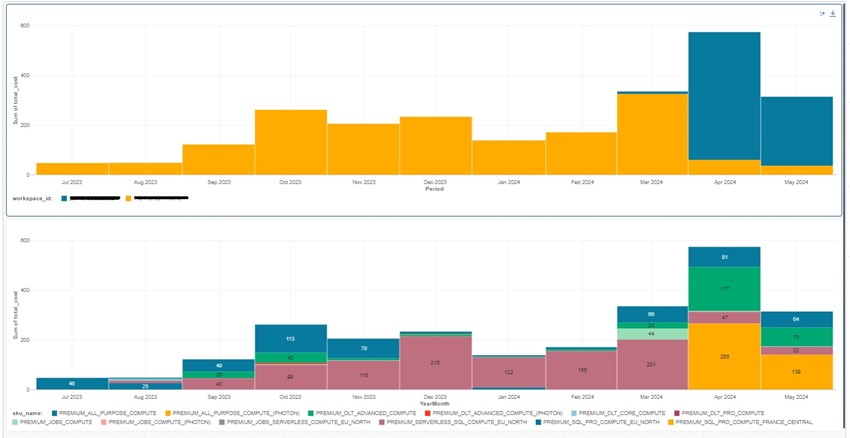
L’application de tags aux objets et aux types de compute Databricks permet une qualification plus précise des analyses de coûts, offrant un suivi personnalisé des dépenses.
Mise en place
Les trois prérequis pour mettre en place les tables systèmes sont :
- Avoir au moins un workspace Databricks avec Unity Catalog d’activé dans le compte Databricks
- Être Admin du compte Databricks
- Générer un Personal Access Token non expiré dans Databricks afin de pouvoir utiliser les API SQL de Databricks
Afficher le statut des tables systèmes du compte Databricks
- Récupérer l’ID du metastore Databricks :
metastore_id = spark.sql("SELECT current_metastore() as metastore_id").collect()[0]["metastore_id"]
metastore_id = metastore_id[metastore_id.rfind(':')+1:]
2. Récupérer l’host du compte Databricks :
host = "https://"+dbutils.notebook.entry_point.getDbutils().notebook().getContext().browserHostName().get()
3. Construire le header du futur appel API grâce à un token access associé au compte exécutant le code :
headers = {"Authorization": "Bearer "+dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()}
4. Exécuter l’appel API permettant de récupérer le statut des tables systèmes du compte Databricks :
import requests
import json
result = requests.get(f"{host}/api/2.0/unity-catalog/metastores/{metastore_id}/systemschemas", headers=headers).json()
5. Afficher le résultat de retour de l’appel API au format JSON :
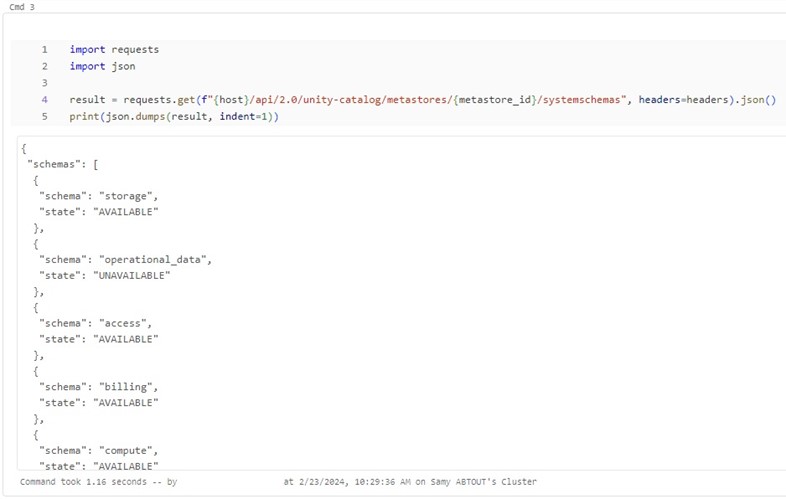
Les tables avec le statut AVAILABLE sont activables, les autres sont soit déjà activées, soient inaccessibles pour le moment.
Activer les tables systèmes
- Prévisualiser les tables qui seront activées :
schemas_to_enable = []
already_enabled = []
others = []
for schema in result['schemas']:
if schema['state'].lower() == "available":
schemas_to_enable.append(schema["schema"])
elif schema['state'].lower() == "enable_completed":
already_enabled.append(schema["schema"])
else:
others.append(schema["schema"])
print(f"Schemas that will be enabled: {schemas_to_enable}")
print(f"Schemas that are already enabled: {already_enabled}")
print(f"Unavailable schemas: {others}")

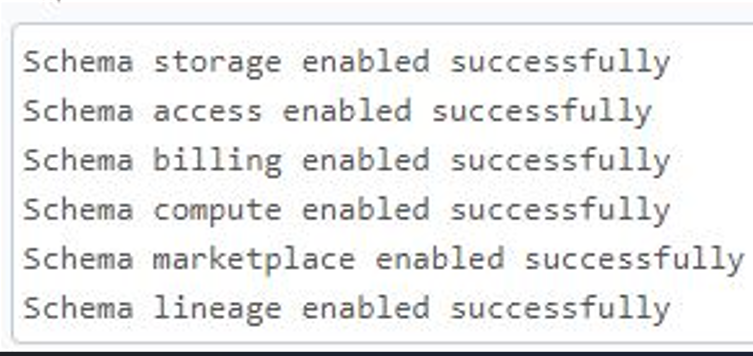
2. Activer les tables système :
from time import sleep
for schema in schemas_to_enable:
host = "https://"+dbutils.notebook.entry_point.getDbutils().notebook().getContext().browserHostName().get()
headers = {"Authorization": "Bearer "+dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()}
r = requests.put(f"{host}/api/2.0/unity-catalog/metastores/{metastore_id}/systemschemas/{schema}", headers=headers)
if r.status_code == 200:
print(f"Schema {schema} enabled successfully")
else:
print(f"""Error enabling the schema `{schema}`: {r.json()["error_code"]} | Description: {r.json()["message"]}""")
sleep(1)
Conclusion
Les tables système Databricks constituent un outil centralisé offrant une vision 360° afin de monitorer et analyser l’activité au sein de votre plateforme. Elles permettent notamment de :
- Garantir la sécurité et la conformité des données
- Optimiser les coûts
- Améliorer les performances
- Favoriser la collaboration et la gouvernance des données
Contrairement aux fichiers de logs traditionnels, souvent fragmentés et difficiles à analyser, les tables système fournissent une structure organisée facilitant l’exploitation des données.
De plus, leur intégration native à la plateforme Databricks permet une utilisation sans outils externes ou de compétences particulières en analyse de données.
En conclusion, les tables système Databricks se révèlent être un atout indispensable pour tous les administrateurs et utilisateurs soucieux de maîtriser leur environnement Databricks.