Samy ABTOUT, DATA ENGINEER
D’après les prévisions publiées par le département de Recherche de Statista en mars 2022, la quantité de données générées dans le monde dépassera 180 zettaoctets en 2025, soit une croissance annuelle moyenne de près de 40 % sur cinq ans. Les bénéfices attendus sont immenses mais l’exploitation de ces données n’est pas sans risque.
En effet, cette explosion de données pose des défis considérables en matière de performances et d’efficacité des systèmes. Les opérations de recherche et d’analyse sur de grandes quantités de données peuvent être extrêmement lentes, voire infaisables, si elles ne sont pas gérées de manière efficace.
C’est dans ce contexte de gestion de très grandes quantités de données que des concepts d’optimisation sont devenus indispensables. Dans cet article, nous explorerons la problématique de l’optimisation des performances dans les projets BigData, et plus précisément ceux utilisant PySpark c’est-à-dire les projets utilisant le framework Spark avec le langage Python. Les techniques étant nombreuses, nous nous concentrerons ici sur deux concepts : l’indexage avec Hyperspace et la colocalisation des données avec Z-Order.
Hyperspace : Un système d'indexage Microsoft Open-source
Hyperspace est un système Microsoft d’indexation open-source utilisé sur Apache Spark permettant la création et la maintenance d’index sur des fichiers de données au format parquet. Il est pris en charge dans Azure Synapse Runtime pour les versions d’Apache Spark allant de 2.4 à 3.2.
Un index est une structure de données redondante organisée permettant d’accélérer certaines recherches. Au même titre qu’un sommaire dans un livre, il permet un lien direct vers les données du fichier d’origine lorsqu’il est utilisé. Voici un exemple d’illustration d’un index créé sur la colonne job d’un fichier listant des utilisateurs :
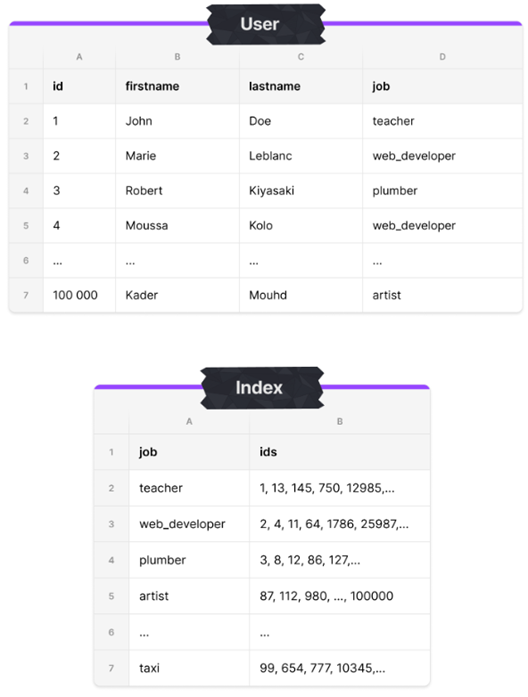
Dans cet exemple, la colonne indexée est la colonne « job ». L’index positionné permet de lister l’ensemble des « ids » associés aux jobs et facilite ainsi les requêtes impliquant la colonne indexée.
L’index permet donc d’optimiser les performances de requêtage lorsqu’un filtre, un tri, une agrégation ou une jointure est effectuée sur les colonnes indexées du fichier.
Hyperspace prend également en charge la mise à jour incrémentielle des index lorsqu’il y a des modifications dans les données. Cela permet de maintenir les index à jour sans avoir à reconstruire totalement l’index à chaque modification. Cette action n’est cependant pas automatique, elle nécessite la mise en place d’un plan de maintenance afin de maintenir l’index à jour.
Z-Order : Une technique de colocalisation de données
Présentation du format Delta
Le format Delta est un format de stockage de données conçu spécifiquement pour les environnements Big Data. Il a été développé par Databricks et est largement utilisé dans l’écosystème Apache Spark. Le format Delta combine les principales fonctionnalités suivantes :
- Les transactions ACID (Atomicité, Cohérence, Isolation et Durabilité) dans Spark
- La validation de schéma
- La possibilité de versionner le fichier
- La lecture et écriture de fichiers en streaming
- La génération de statistiques à chaque opération d’ajout de données. Celles-ci contiennent :
- Des informations telles que la taille et le nombre de lignes de potentielles partitions
- Des statistiques sur les valeurs uniques, les valeurs minimales et maximales des colonnes
- Des échantillons représentatifs des données, qui permettent d’obtenir des estimations approximatives des agrégations et des jointures sans avoir à traiter toutes les données.
Le format Delta collecte ces statistiques à la volée permettant l’utilisation de l’opération de Data Skipping.
Présentation du Data Skipping
Le Data Skipping, apparu dans la version 1.2.0 de Delta Lake, est une fonctionnalité native des fichiers Delta. Il s’appuie sur les métadonnées précédemment citées pour améliorer les performances de requêtage. Le Data Skipping examine la requête entrante et estime quels blocs de données doivent être lus en s’appuyant sur les statistiques. Le fait de ne pas devoir lire tous les blocs de données permet de réduire le temps de traitement.
Ce procédé est d’autant plus efficace lorsque les données au sein du fichier sont ordonnées ou colocalisées de manière optimale.
Présentation du Z-Order
Z-Order est une technique permettant de colocaliser les données au sein d’un même fichier, apparue dans la version Delta Lake 2.0.0. Le but est de réorganiser les données de manière à ce que les éléments proches soient également proches dans le fichier, c’est-à-dire que les éléments similaires ou spatialement proches soient regroupés physiquement dans le fichier. Ainsi, le nombre de lectures nécessaires pour récupérer les informations pertinentes est réduit, ce qui minimise les accès disque et améliore les performances globales de requêtage.
Voici une illustration du fonctionnement de Z-Order, couplé au Data Skipping :
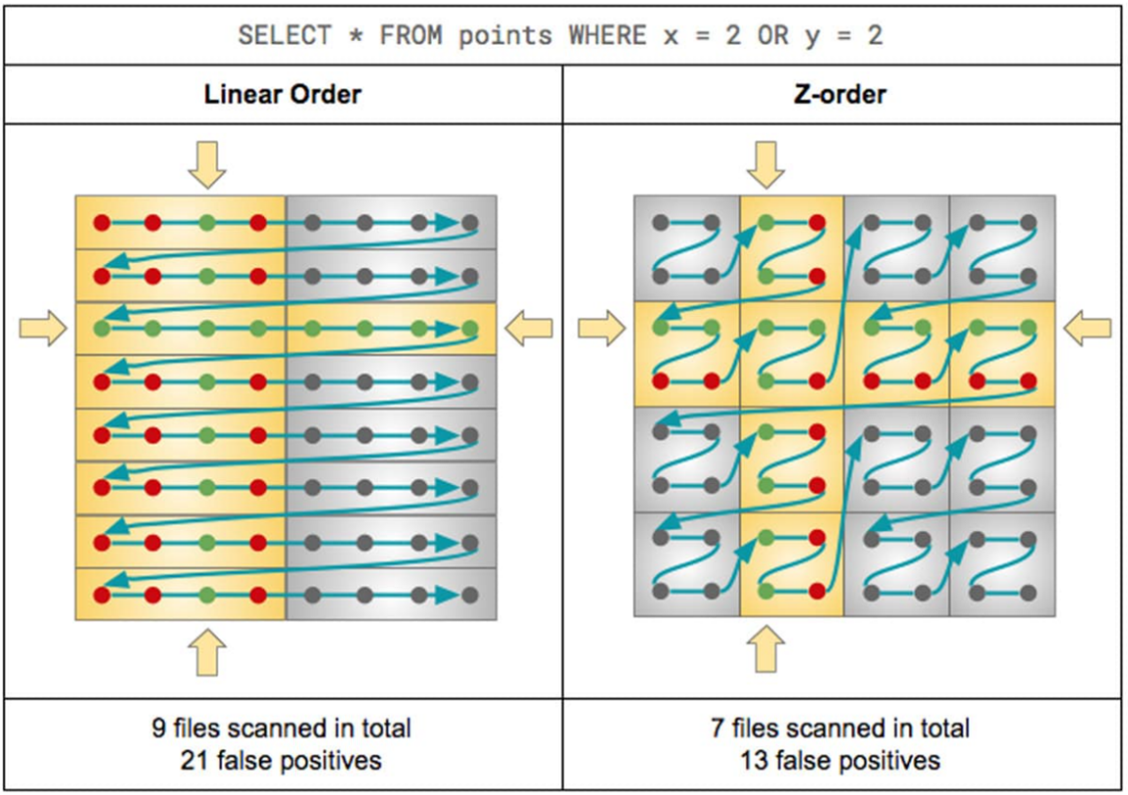
Cette illustration est la comparaison du traitement d’une requête avec conditions sur un fichier classique et un fichier avec un Z-Order d’appliqué :
- Dans le premier cas, neuf fichiers ont dû être lus (les cases jaunes) avec 21 lignes de données qui ne respectent pas les conditions de la requête (les points rouges) afin de pouvoir exécuter la requête.
- Dans le deuxième cas, sept fichiers ont été lus avec 13 lignes de données caduques.
La diminution du nombre de fichiers à scanner et du nombre de données caduques est liée à l’application du Data Skipping sur des données colocalisées.
Afin d’identifier les potentiels gains de performance de ces deux concepts, nous allons comparer les temps de réponse d’une même requête sur quatre fichiers parquet portant le même jeu de données :
- Un fichier parquet classique
- Un fichier Delta parquet classique
- Un fichier parquet indexé avec Hyperspace
- Un fichier Delta parquet avec Z-Order
Voici les spécifications utilisées lors des tests de performance :
Ressource : Azure Synapse
Spark pool : Small 4 vcore / 32gb – 3 nœuds / 2 exécuteurs et 8 cœurs
Version de Spark :
- 3.2 pour Hyperspace
- 3.3 pour Z-Orde
La version de Spark diffère pour les tests du Z-Order car à l’écriture de cet article, la version Delta Lake 2.0.0 n’est installée que dans la version Spark 3.3 dans le runtime Azure Synapse.
Protocole de test
Le jeu de données des taxis jaunes new-yorkais mis à disposition par Microsoft sera utilisé pour les tests. Voici la source : NYC Taxi and Limousine yellow dataset – Azure Open Datasets | Microsoft Learn
Préparation des jeux de données de test
Le Dataset a été enregistré au format parquet sur un compte de stockage ADLS gen2 et compte 4.7 milliards de lignes. Celui-ci est très volumineux ce qui permettra d’imiter un jeu de données BigData et de mettre en évidence de manière significative les potentiels gains de performances. Il sera utilisé pour les tests du fichier parquet et d’Hyperspace.
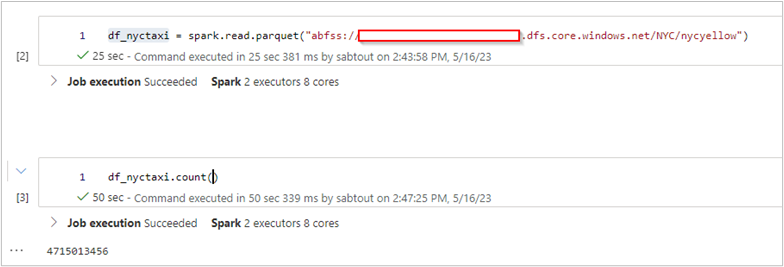
Enfin, une copie de ce Dataset est faite, au format Delta parquet afin de tester le Z-Order.
df_nyctaxi.write.format("delta").mode("overwrite").save("abfss://xxx@xxx.dfs.core.windows.net/NYC/nycyellow_delta"
Nous avons ainsi deux jeux de données identiques, l’un au format parquet et l’autre au format Delta parquet.
Mise en place d’Hyperspace
La librairie Hyperspace est nativement intégrée dans Azure Synapse Runtime pour Apache Spark 3.2. Nous allons maintenant voir les étapes nécessaires à la mise en place et l’activation d’Hyperspace :
- Désactiver l’AutoBroadcastJoin sur Spark. C’est une technique d’optimisation utilisée lors des opérations de jointures dans les traitements distribués entre un ensemble de données volumineux et un autre beaucoup plus petit. Elle vise à améliorer les performances en réduisant les mouvements de données entre les nœuds de calcul. Cependant, Hyperspace utilise la fonctionnalité SortMergeJoin qui est automatiquement désactivée lorsque l’AutoBroadcastJoin est activé. C’est également une technique d’optimisation, qui permet de combiner et trier les ensembles de données à joindre avant l’opération de jointure.
# Disable BroadcastHashJoin
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1
2. Créer une instance Hyperspace
from hyperspace import *# Create an instance of Hyperspace
hyperspace = Hyperspace(spark)
3. Déterminer la configuration de l’index que l’on souhaite créer
nyctaxi_IndexConfig = IndexConfig("nyctaxi_vId",["vendorId"],["tripDistance", "passengerCount"])
4. Créer l’index au fichier parquet nycyellow
df_nyctaxi = spark.read.parquet("abfss://xxx@xxx.dfs.core.windows.net/NYC/nycyellow")
hyperspace.createIndex(df_nyctaxi, nyctaxi_IndexConfig)
Mise en place du Z-Order
On applique l’opération de Z-Order sur la colonne vendorId au fichier delta nycyellow_delta :
from delta.tables import *deltaTable = DeltaTable.forPath(spark, "abfss://xxx@xxx.dfs.core.windows.net/NYC/nycyellow_delta")
deltaTable.optimize().executeZOrderBy("vendorId")
Exécution des tests
Une même requête est exécutée sur les quatre jeux de données suivants :
- nycyellow au format parquet classique
- nycyellow_delta sans l’application du Z-Order
- nycyellow avec Hyperspace activé
- nycyellow_delta avec l’application du Z-Order
Voici la requête :
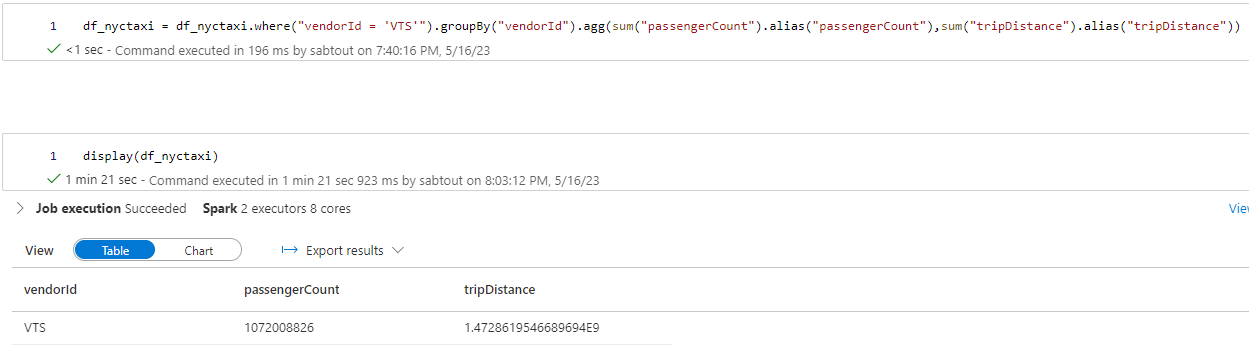
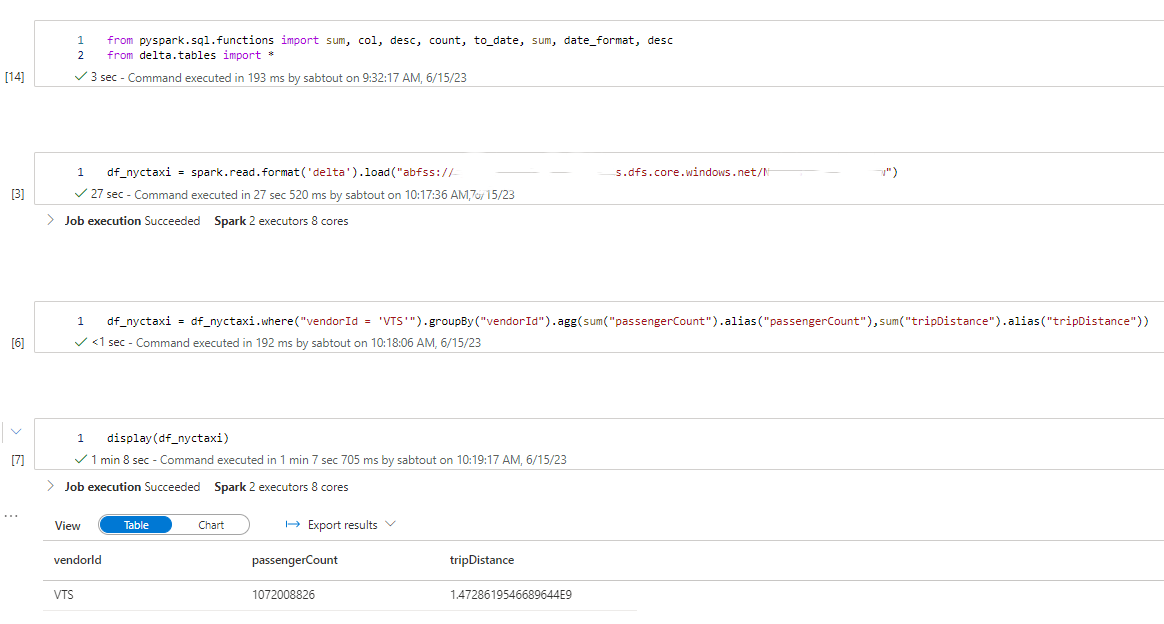
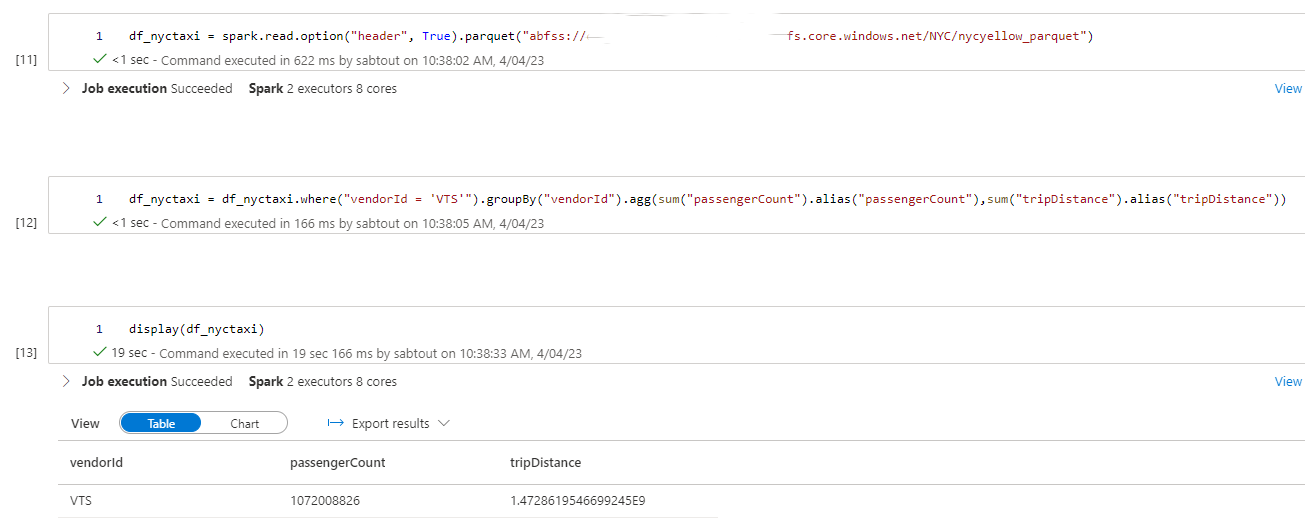
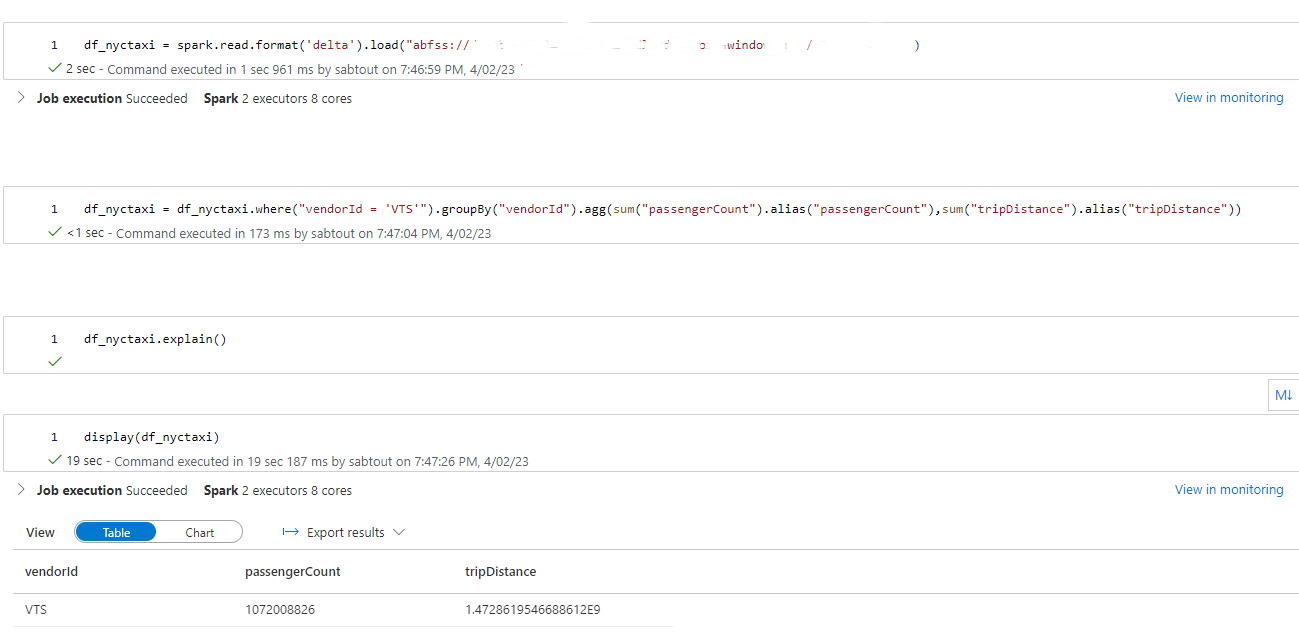
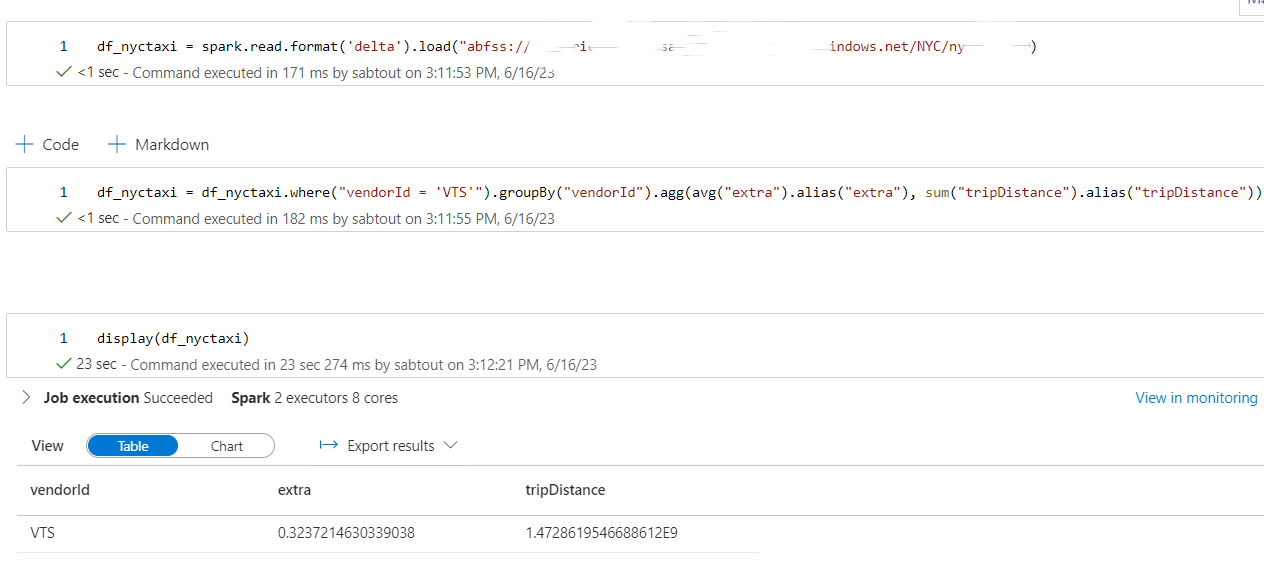
df_nyctaxi = df_nyctaxi.where("vendorId = 'VTS'").groupBy("vendorId").agg(sum("passengerCount").alias("passengerCount"),sum("tripDistance").alias("tripDistance"))
Nous appliquons un filtre sur le champ vendorId utilisé comme colonne d’indexation et de colocalisation afin de mettre en évidence les performances d’Hyperspace et du Z-Order.
Avant chaque requête, le cache est vidé afin de ne pas fausser les résultats obtenus.
spark.catalog.clearCache()
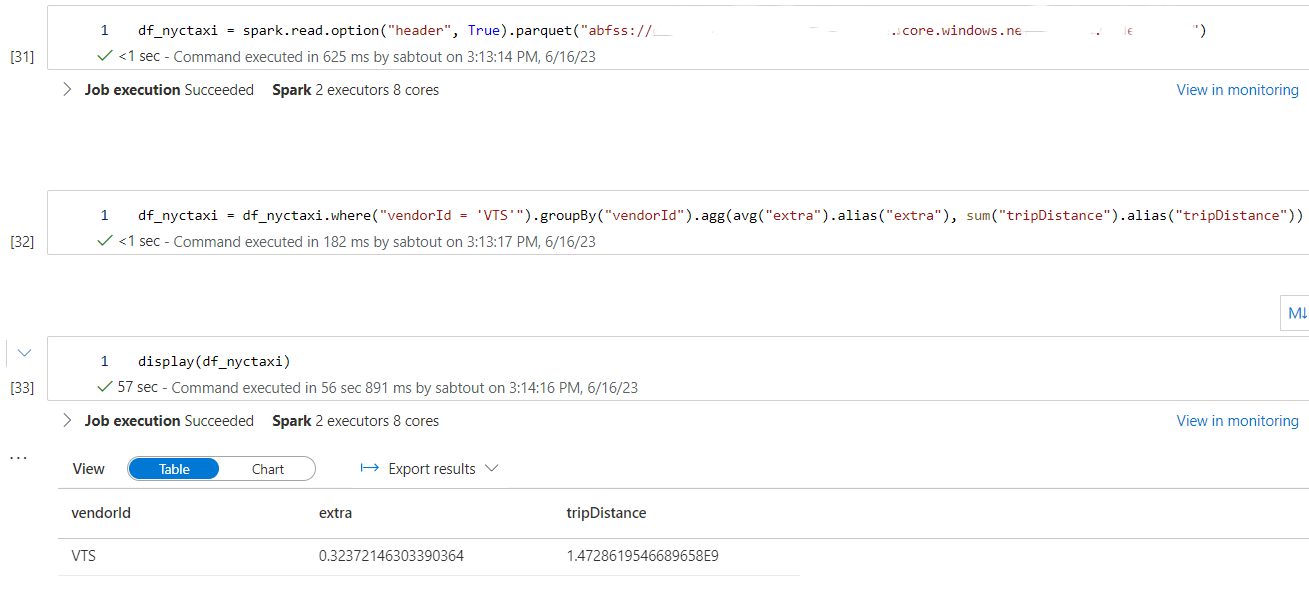
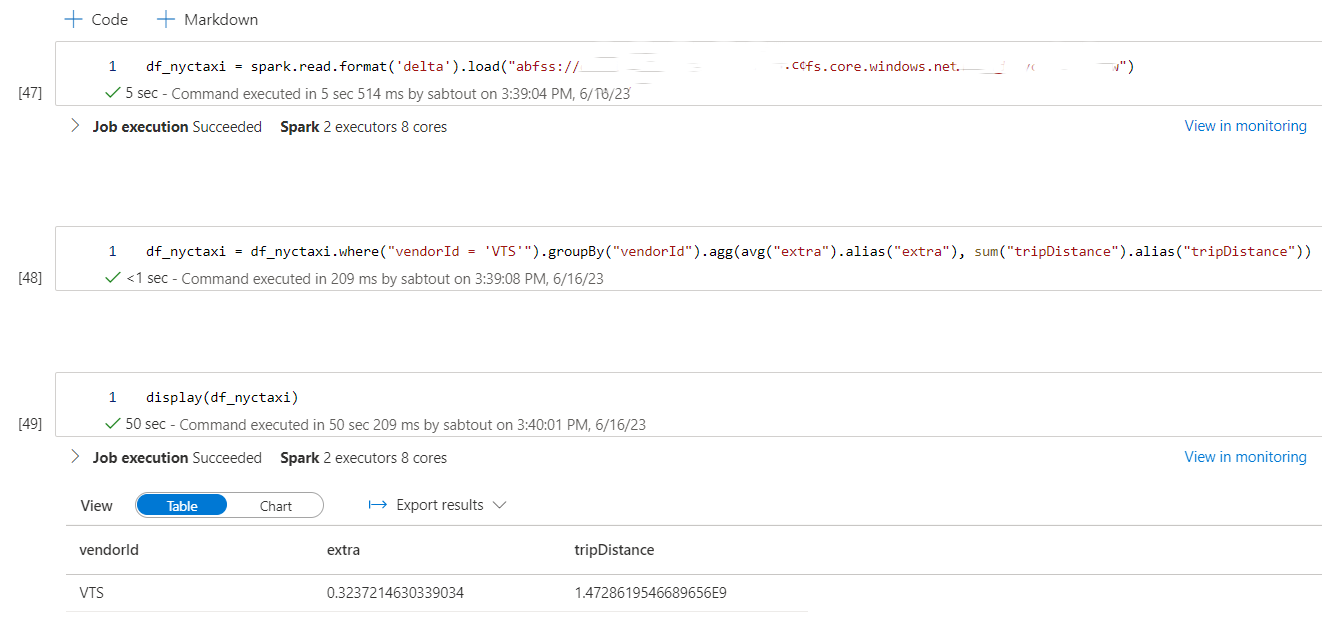
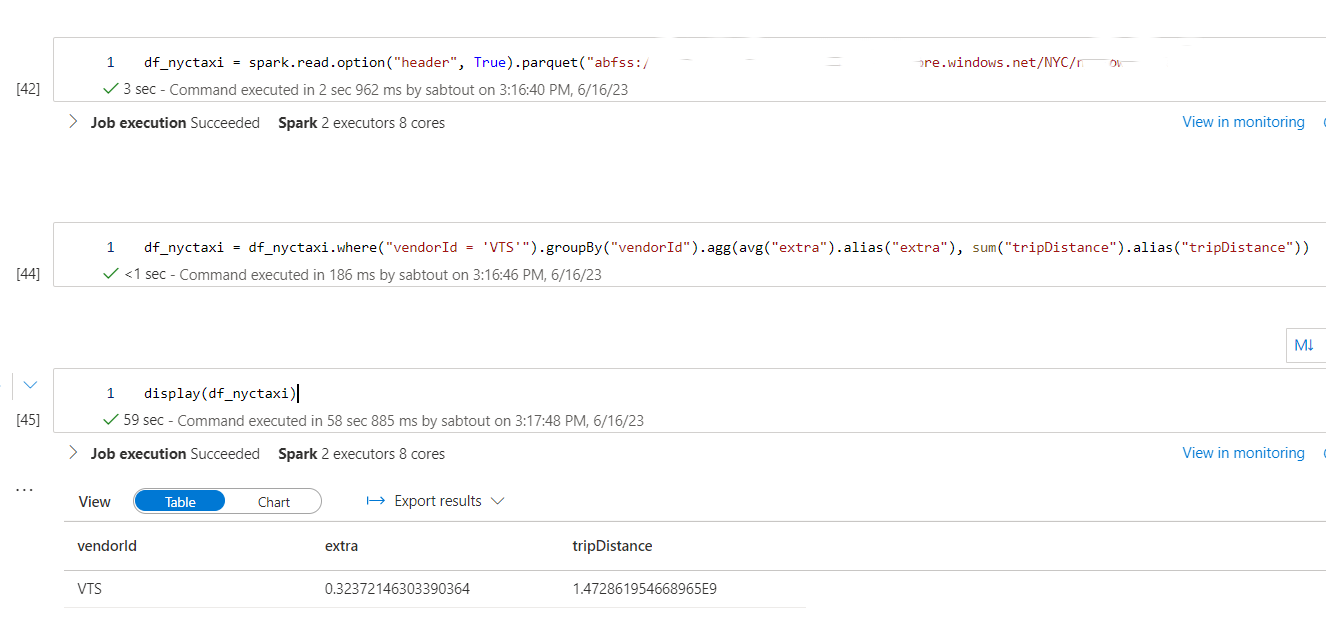
Enfin, nous appliquons le même mode opératoire, avec cette fois-ci une requête affichant une colonne qui n’est pas présente dans le contexte d’optimisation d’Hyperspace :
df_nyctaxi = df_nyctaxi.where("vendorId = 'VTS'").groupBy("vendorId").agg(avg("extra").alias("extra"), sum("tripDistance").alias("tripDistance"))
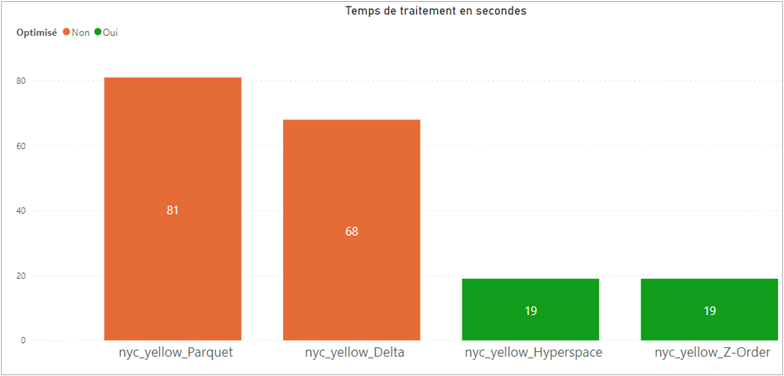
Les résultats de la première requête démontrent l’impact significatif d’Hyperspace et de Z-Order sur les performances de requêtage. En utilisant ces techniques d’optimisation, nous avons observé des temps de requêtage divisés par 4 comparé à un fichier Parquet classique et 3,5 fois comparé à un fichier Delta.
En ce qui concerne Hyperspace, l’amélioration peut être attribuée à l’indexation intelligente des données qui lui permet d’éviter la lecture des sections de données inutiles lors de l’exécution des requêtes.
Nous pouvons également observer que le format Delta Parquet est légèrement plus performant que le format Parquet dû à l’action du Data Skipping (diminution de 16%). Cependant, la colocalisation des données permet d’améliorer les performances du Data Skiping de façon flagrante avec une diminution de temps de traitement de plus de 70% entre le fichier Delta sans Z-Order et celui avec.
Passons désormais à l’analyse des résultats de la seconde requête :
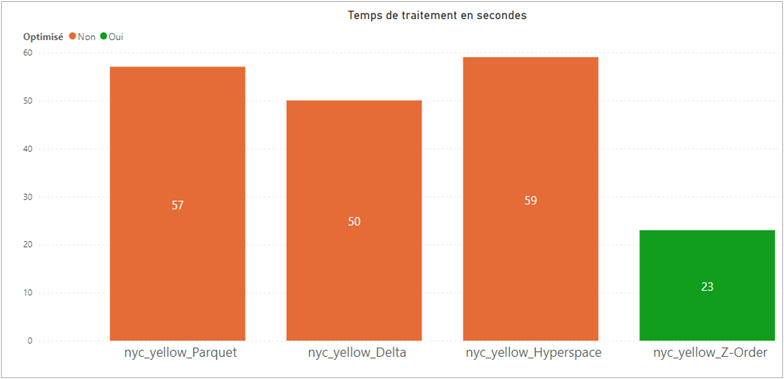
Lorsque la requête comporte des colonnes qui ne sont pas présentes dans le contexte d’optimisation d’Hyperspace, la fonctionnalité n’est pas utilisée par le moteur Spark. C’est pour cela que nous pouvons observer des temps de traitement similaires entre le fichier Parquet et celui qui est supposé utiliser l’index Hyperspace.
De plus, on remarque une réduction du temps de traitement entre le fichier Delta et le fichier Parquet, similaire à celle observée pour la première requête, grâce à l’utilisation du Data Skipping.
Enfin, le temps de traitement est réduit de moitié entre le fichier Delta sans Z-Order et celui qui en fait usage.
Vous retrouverez le détail des exécutions ainsi que les plans d’exécutions en annexe (Fig.5 -> 14)
L’utilisation d’Hyperspace et de Z-Order sur des fichiers Parquet se révèle être une stratégie efficace pour optimiser les performances de requêtage. Ces deux techniques offrent des améliorations significatives des temps de réponse et permettent de réduire la consommation de ressources lors de l’exécution de requêtes sur des données Parquet.
Avec son approche d’indexation intelligente, Hyperspace propose une solution de création d’index se traduisant par une amélioration des performances lors des interrogations de données, tout en simplifiant la gestion et la maintenance des index. Toutefois, cette fonctionnalité ne s’active que lorsque l’exhaustivité des colonnes utilisées dans la requête sont bien spécifiées à de la création de l’index.
La technique de Z-Order offre une réorganisation efficace des données, améliorant les liens entre elles. Couplée au Data Skipping, elle permet également une lecture des fichiers optimisée grâce aux métadonnées récoltées pendant les opérations de Z-Order, en ignorant les blocs de données non pertinents.
Cependant, ces opérations nécessitent un investissement. En effet, la création de l’index pour Hyperspace et l’application de la colocalisation pour Z-Order sont des opérations coûteuses en matière de temps. Pour nos tests, les deux opérations ont duré près d’1h30. Il faut également pouvoir maintenir à jour l’index et la colocalisation lorsque de nouvelles lignes arrivent dans le fichier (cas d’usage par exemple d’une couche Silver ou Gold dans un DeltaLakeHouse). Dans ce cas, il faut voir ces deux opérations comme des tâches de maintenance et les exécuter après l’alimentation des couches Silver et Gold.
Ce sont ainsi deux techniques qui permettent un réel gain au niveau de requêtage de données, mais qui nécessitent la mise en place d’un plan de maintenance. Hyperspace est compatible avec les versions de Spark de 2.4 à 3.2, tandis que le Z-Order peut être utilisé avec les versions de Delta Lake 2.0.0 et ultérieures.
Annexes