Rafik BELLAHSENE, DATA ARCHITECT
Au sein d’une organisation, les données jouent un rôle essentiel dans divers domaines tels que les campagnes marketing, les activités commerciales et la prise de décisions. Par conséquent, les processus d’extraction, de transformation et de chargement de données (ETL) sont devenus des pratiques indispensables pour garantir le développement durable d’une entreprise. C’est pourquoi il est crucial de s’assurer de la fiabilité des données avant de les partager avec les différents départements de l’entreprise, afin d’éviter toute prise de décision biaisée pouvant entraîner des conséquences désastreuses.
Dans cet article, je vais vous présenter un outil open-source de contrôle et de validation de l’intégrité et de la qualité des données au sein d’un datawarehouse.
Great Expectations est une bibliothèque Python open-source permettant aux data engineers de vérifier la qualité de leurs données à travers une série de tests unitaires et de contrôles automatisés appelés « Expectations », et de générer en sortie des rapports facilitant l’exploitation et la compréhension des différents périmètres de données (cf. figure ci-dessous).
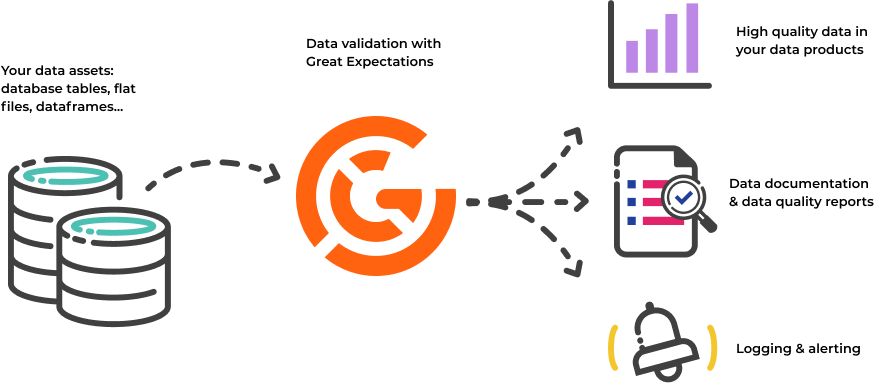
Source : https://docs.greatexpectations
Avant de rentrer dans le détail, il est important de se familiariser avec le lexique de Great Expectations.
Great Expectations offre de nombreuses fonctionnalités, notamment :
- Les attentes (Expectations): représentent les exigences techniques que les données doivent respecter pour être considérées fiables et justes. Par exemple, préciser que les valeurs d’une colonne doivent être comprises entre 0 et 10.
- Le profilage automatique des données (Automated data profiling): permet de rapidement comprendre la donnée en fournissant un résumé de sa structure et de sa distribution statistique, et génère automatiquement une suite d’attentes de base en fonction de ce qui est observé dans les données.
- Les Datadocs : rapports de qualité de données au format HTML. Ils contiennent la liste des attentes des résultats de validation des données de chaque exécution.
Dans cet article, je vais vous montrer deux exemples d’utilisation de Great Expectations pour traiter :
- le nettoyage des données.
- la validation de l’intégrité des données.
Pour illustrer ces deux cas d’utilisation, je vais utiliser un jeu de données collecté à partir de Kaggle (accessible via le lien fourni). Cet ensemble de données contient une liste de restaurants de la ville de Bangalore enregistrés dans l’application Zomato (l’équivalent indien de La Fourchette).
Pour ce tutoriel, il est nécessaire d’avoir à disposition :
- Un espace de travail/workspace Azure Databricks
- Un datalake storage Azure
- Un Aure Key Vault
- Un Service Principal Name (SPN) ayant le droit « Storage Blob Data Contributor» au sein du datalake cité ci-dessus
- Python >= 3.7
- Spark >= 3.0
Enregistrement des informations du service principal dans le key Vault
Les 3 informations suivantes, relatives au SPN, sont stockées en tant que Secret au niveau du Key Vault :
- « sandbox-client-id» : ID Client du SPN
- « sandbox-spn-secret » : Valeur du secret lié au SPN
- « tenant-id» : ID du tenant Azure dans lequel est enregistré le SPN et le workspace Azure Databricks
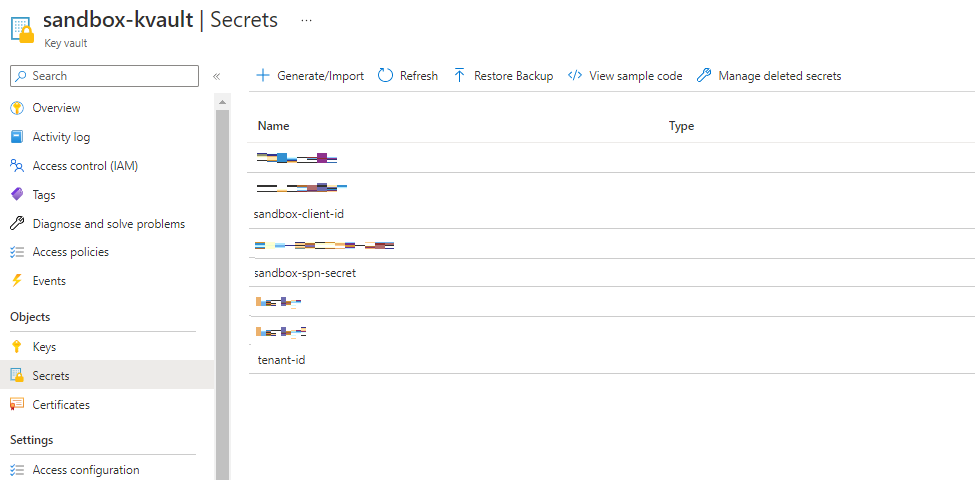
Création d’un secret scope sur Azure Databricks
Pour la suite, il est nécessaire de créer un secret scope « databricks-scope ». Partant du postulat que l’environnement Databricks est connu et maitrisé par le lecteur, je ne détaille pas ici la marche à suivre.
Pour ceux qui souhaitent avoir plus d’informations sur le sujet, je vous renvoie à la documentation de Microsoft qui décrit cela pas à pas (c.f Lien).
Création d’un mount point DBFS
DBFS est le système de fichiers distribué de Databricks. Il fournit une couche d’abstraction au-dessus du stockage objet permettant aux utilisateurs de manipuler les fichiers et les données de manière transparente, sans avoir à se soucier de la gestion des nœuds de stockage ou de la maitrise des API de stockage dans le cloud (par exemple Azure Storage API).
La création du mount point permet de créer un lien entre l’espace de travail Databricks et le compte de stockage Azure.
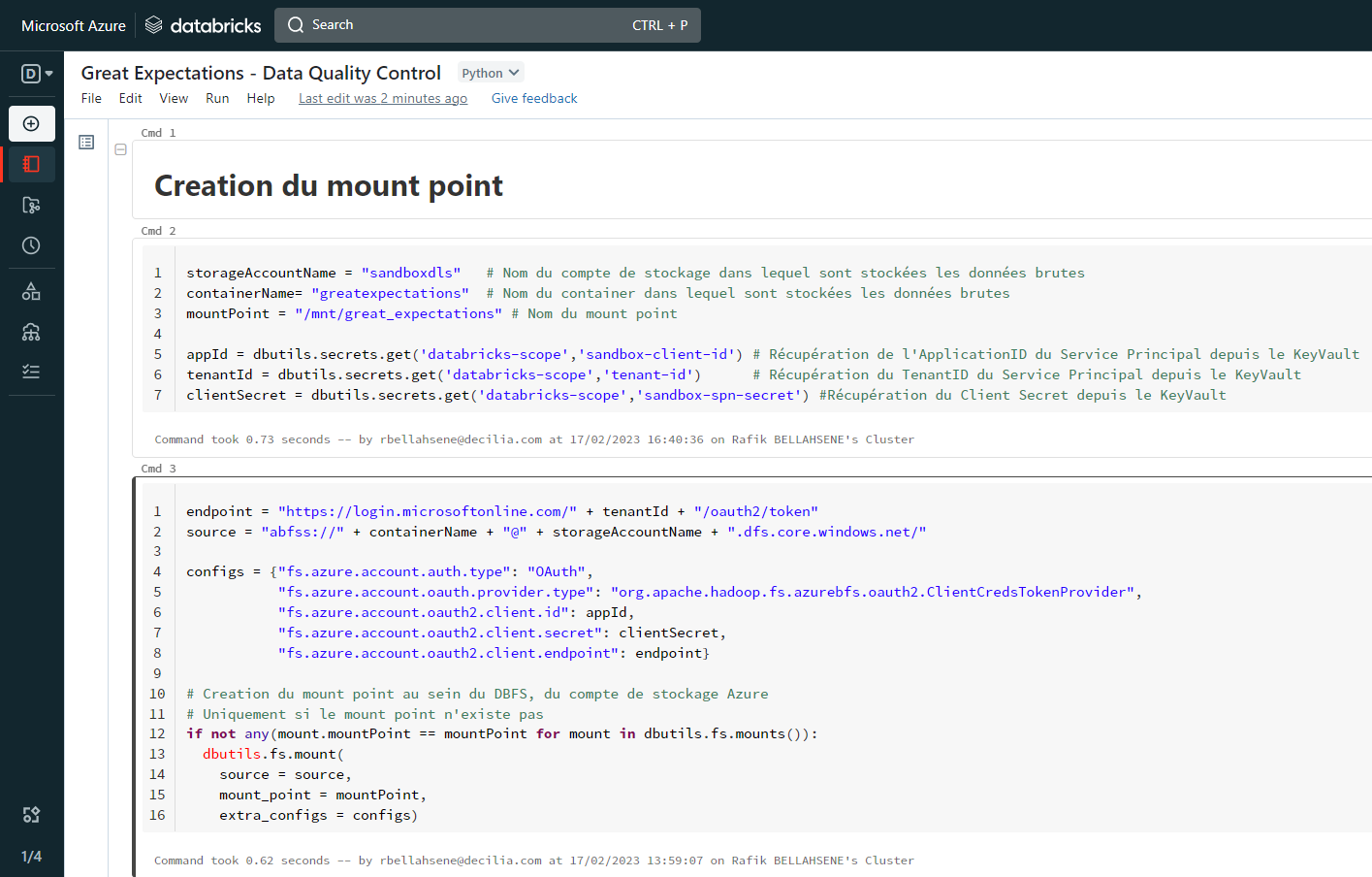
storageAccountName = "NomDuCompteDeStockage"
containerName= "NomDuContainer"
mountPoint = "NomDuMountPoint"
appId = dbutils.secrets.get('VotreSecretScope','sandbox-client-id')
tenantId = dbutils.secrets.get('VotreSecretScope','tenant-id')
clientSecret = dbutils.secrets.get('VotreSecretScope','sandbox-spn-secret')
endpoint = "https://login.microsoftonline.com/" + tenantId + "/oauth2/token"
source = "abfss://" + containerName + "@" + storageAccountName + ".dfs.core.windows.net/"
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": appId,
"fs.azure.account.oauth2.client.secret": clientSecret,
"fs.azure.account.oauth2.client.endpoint": endpoint}
# Création du mount point au sein du DBFS, du compte de stockage Azure
# Uniquement si le mount point n'existe pas
if not any(mount.mountPoint == mountPoint for mount in dbutils.fs.mounts()):
dbutils.fs.mount(source = source,mount_point = mountPoint,extra_configs = configs)
Installation du package Great Expectations
L’installation du package est réalisé via la commande suivante :
! pip install great-expectations
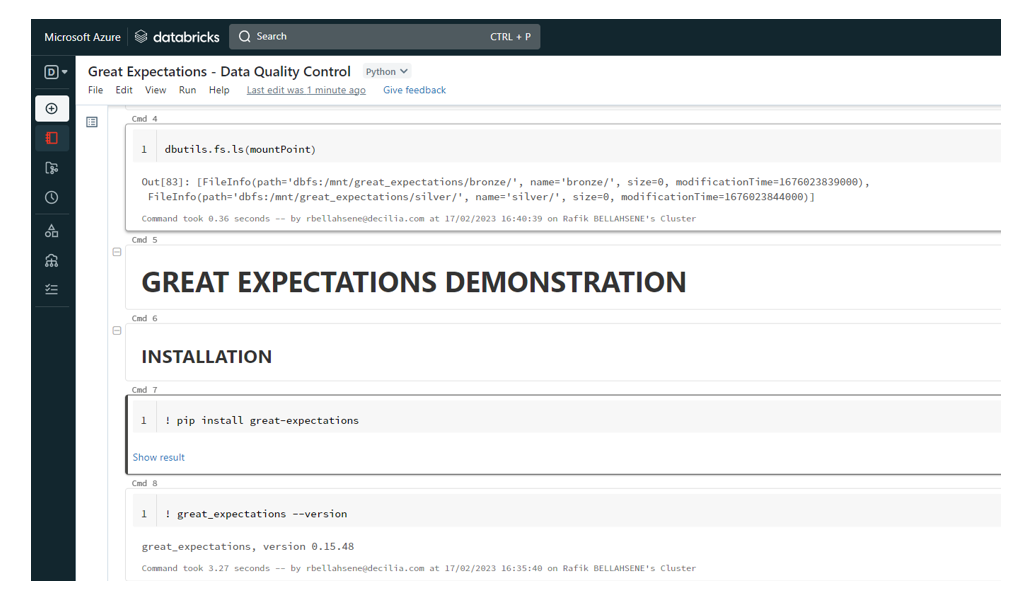
Afin de vérifier que Great Expectations est correctement installé, il suffit d’exécuter la commande
! great_expectations --version
Maintenant que l’environnement est correctement configuré, explorons le premier cas d’utilisation qui concerne le nettoyage des données avec Great Expectations.
Objectifs
Avant de charger les données dans la base cible, nous souhaitons les nettoyer afin de :
- Conserver uniquement les restaurants :
- Dont le lien Zomato est renseigné et correspond au format URL
- Qui acceptent les commandes en ligne
- Qui acceptent les réservations par téléphone et qui ont un numéro de téléphone valide
- Supprimer les restaurants dont la notation est erronée
Démarche
Pour ce faire, nous allons procéder en plusieurs étapes :
1. Chargement du dataset
Tout d’abord, je charge le contenu du fichier « zomato.csv » dans un dataframe, en y accédant par le biais du mount point créé précédemment et donnant accès au compte de stockage.
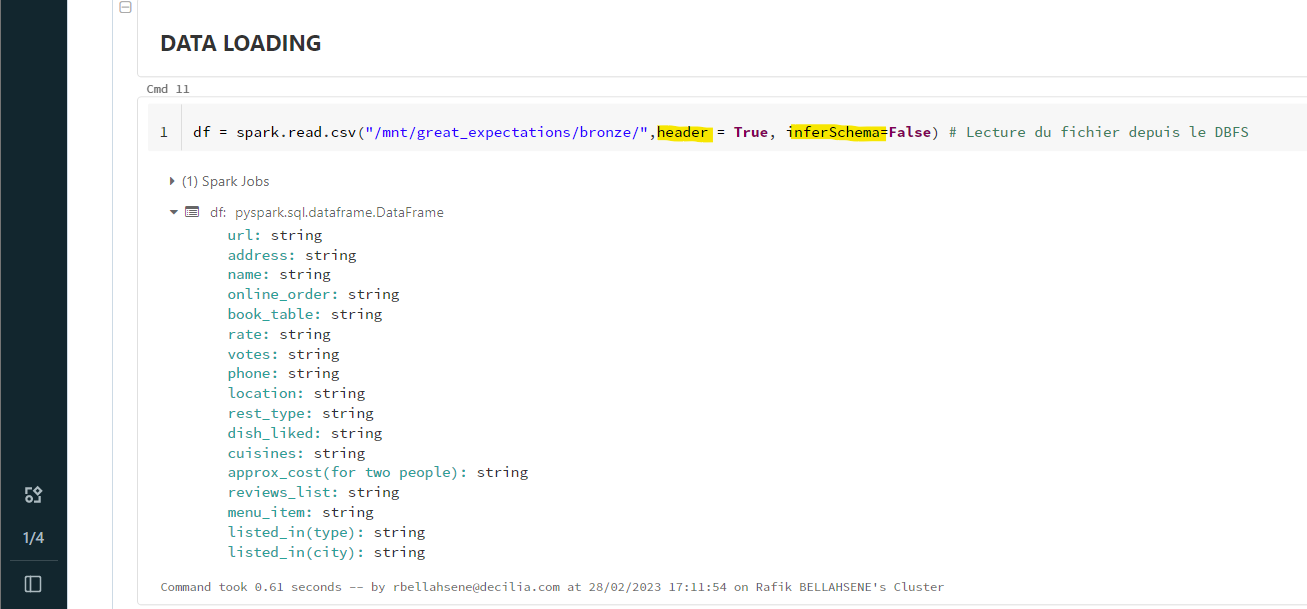
# Lecture du fichier depuis le DBFS
df = spark.read.csv("/mnt/great_expectations/bronze/",header = True, inferSchema=False)
Vous remarquerez que je fais appel à la fonction native Spark « read.csv () » permettant de lire des fichiers CSV. Lors de mon appel, je précise 2 paramètres importants :
- Header = True : permet d’utiliser la première ligne de mon dataset en tant qu’en-têtes de colonnes.
- inferSchema = False : évite au moteur Spark d’automatiquement typer les colonnes en se basant sur le 1er Cette démarche peut introduire un typage incorrect si le 1er enregistrement est erroné.
Le dataset ainsi chargé est constitué de :
- 17 colonnes
- 71 730 lignes

Parmi toutes ces colonnes, nous ne conservons que celles qui nous intéressent :
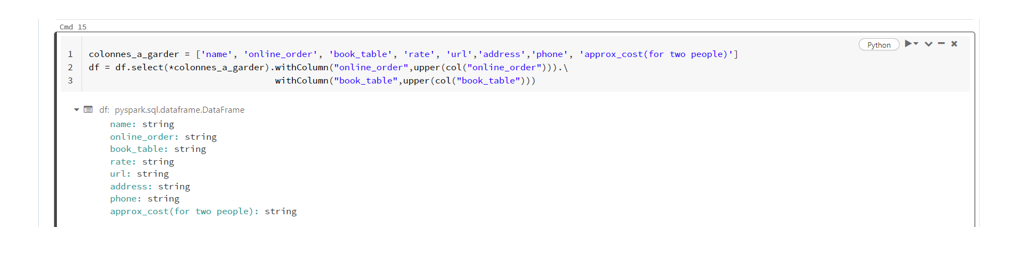
colonnes_a_garder = ['name', 'online_order', 'book_table', 'rate', 'url','address','phone', 'approx_cost(for two people)']
df = df.select(*colonnes_a_garder).withColumn("online_order",upper(col("online_order"))).\
withColumn("book_table",upper(col("book_table")))
Je spécifie les noms des colonnes à conserver dans la variable colonnes_a_garder.
Ensuite, j’effectue deux opérations de transformation (passage des chaînes de caractères en majuscules) sur les champs online_order et book_table pour les harmoniser et faciliter leur manipulation.
2. Visualisation du dataset
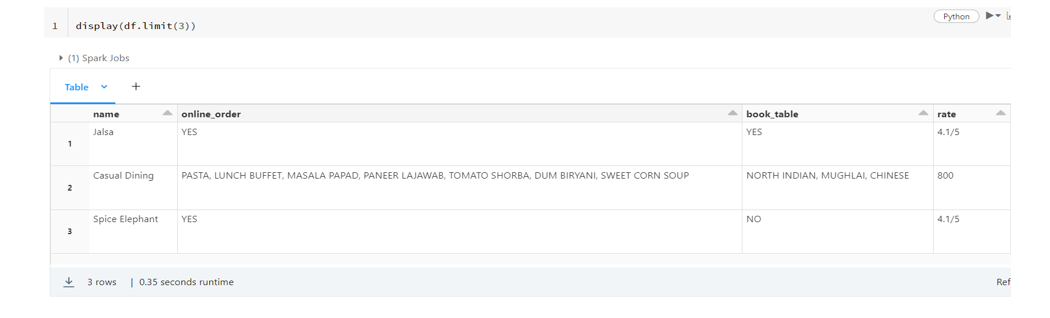
Lorsque l’on parcourt rapidement le contenu du dataset, on remarque d’ores et déjà quelques imperfections sur les données. Je vais donc procéder au nettoyage de ces données afin de pouvoir les exploiter par la suite.
3. Nettoyage des données
Pour commencer, je transforme mon dataset PySpark en objet SparkDFDataset afin de faciliter l’application des attentes de Great Expectations.
La classe SparkDFDataset de Great Expectations est utilisée pour encapsuler les fonctionnalités d’un dataframe PySpark dans un objet manipulable qui peut être utilisé avec les fonctions de validation de Great Expectations.
from great_expectations.dataset import SparkDFDataset# Transformation du dataset en classe maniable par Great Expectations
ge_df = SparkDFDataset(df)
Dans un deuxième temps, j’ai mis en place les attentes (Expectations) que le dataset doit respecter afin de répondre à notre besoin :
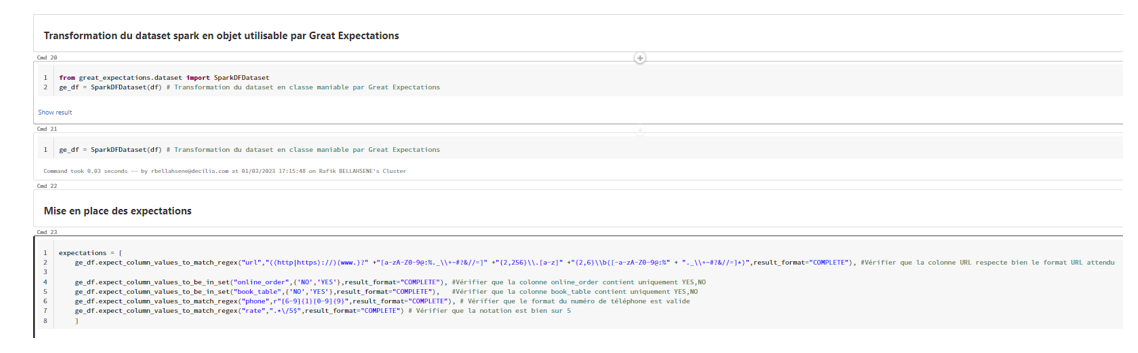
Dans cet exemple, la liste des attentes de qualité de données est la suivante :
- expect_column_values_to_match_regex(« url »,…) : Vérifie que la colonne « url » respecte bien le format d’une URL en utilisant une expression régulière.
- ((http|https)://) : signifie que l’URL doit commencer par http:// ou https://
- (www\.)? : est optionnel et signifie qu’un « » peut être présent
- [a-zA-Z0-9@:%._\\+~#?&//=] : signifie que l’URL doit contenir des caractères alphanumériques, ainsi que certains caractères spéciaux couramment utilisés dans les URL.
- {2,256} : signifie que le nom de domaine doit contenir entre 2 et 256 caractères.
- \\.[a-z]{2,6} : signifie que le domaine doit se terminer par une extension de domaine valide, contenant entre 2 et 6 lettres minuscules.
- \\b([-a-zA-Z0-9@:%._\\+~#?&//=]*) : Cela signifie que l’URL peut contenir des caractères supplémentaires (y compris des caractères spéciaux) après le nom de domaine et l’extension.
- expect_column_values_to_be_in_set(« online_order »,…) : Vérifie que la colonne « online_order » ne contient que les valeurs « YES » ou « NO ».
- expect_column_values_to_be_in_set(« book_table »,…) : Vérifie que la colonne « book_table » ne contient que les valeurs « YES » ou « NO ».
- expect_column_values_to_match_regex(« phone »,…) : Vérifie que le format de la colonne « phone » est valide en utilisant une expression régulière. Cette expression vérifie la validité d’un numéro de téléphone indien.
- [6-9]{1} : signifie que le premier chiffre du numéro doit être compris entre 6 et 9 inclus.
- [0-9]{9} : signifie que les neuf chiffres suivants du numéro de téléphone doivent être compris entre 0 et 9.
- expect_column_values_to_match_regex(« rate »,…) : Vérifie que la colonne « rate » est une notation sur 5 en utilisant une expression régulière.
expectations = [
#Vérifier que la colonne URL respecte bien le format URL attendu
ge_df.expect_column_values_to_match_regex("url","((http|https)://)(www.)?" +"[a-zA-Z0-9@:%._\\+~#?&//=]" +"{2,256}\\.[a-z]" +"{2,6}\\b([-a-zA-Z0-9@:%" + "._\\+~#?&//=]*)",result_format="COMPLETE"),
#Vérifier que la colonne online_order contient uniquement YES,NO
ge_df.expect_column_values_to_be_in_set("online_order",{'NO','YES'},result_format="COMPLETE"),
#Vérifier que la colonne book_table contient uniquement YES,NO
ge_df.expect_column_values_to_be_in_set("book_table",{'NO','YES'},result_format="COMPLETE"),
# Vérifier que le format du numéro de téléphone est valide
ge_df.expect_column_values_to_match_regex("phone",r"[6-9]{1}[0-9]{9}",result_format="COMPLETE"),
# Vérifier que la notation est bien sur 5
ge_df.expect_column_values_to_match_regex("rate",".*\/5$",result_format="COMPLETE")
Ensuite, je valide l’ensemble des attentes (expectations) définies pour le dataset ge_df. :
validation_result = ge_df.validate()
validation_result.meta["expectation_suite_name"] = expectation_suite.expectation_suite_name
Enfin, je génère une page HTML pour visualiser les résultats de la validation stockés dans la variable validation_result :
validation_view = ValidationResultsPageRenderer().render(validation_result)
displayHTML(DefaultJinjaPageView().render(validation_view))
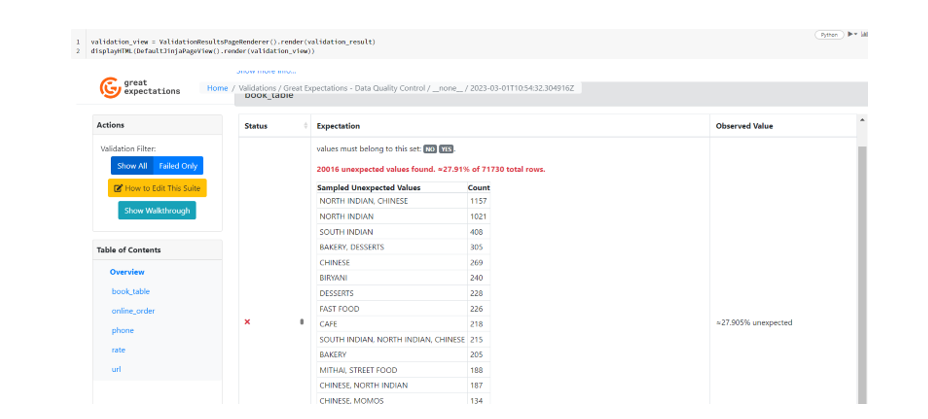
Après avoir effectué une validation avec Great Expectations sur mon DataFrame, je procède à la suppression des données aberrantes.
Pour cela, je parcours chaque colonne en identifiant les valeurs invalides à l’aide de la liste retournée par « validation_result[« results »][i][« result »][« unexpected_list »] », puis je les élimine en utilisant la méthode filter().
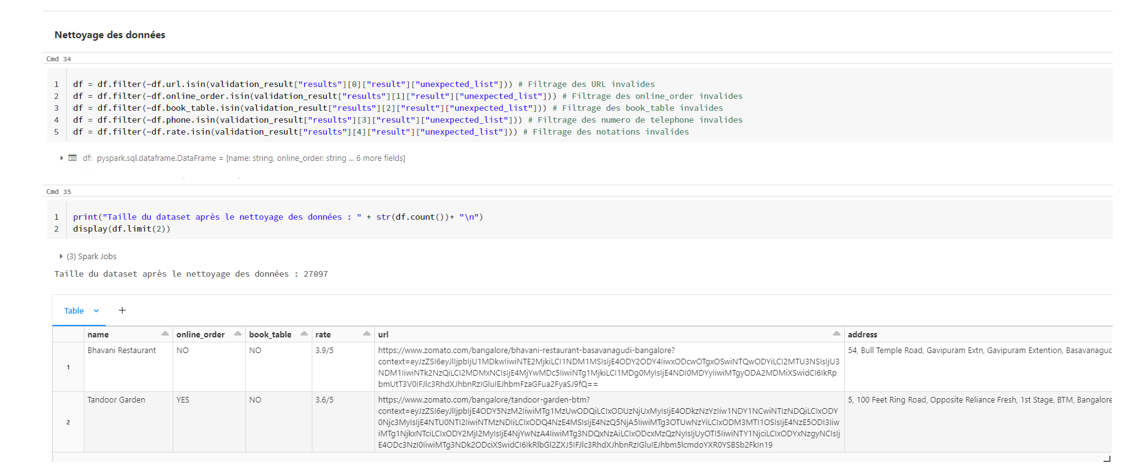
# Filtrage des URL invalides
df = df.filter(~df.url.isin(validation_result["results"][0]["result"]["unexpected_list"]))
# Filtrage des online_order invalides
df = df.filter(~df.online_order.isin(validation_result["results"][1]["result"]["unexpected_list"]))
# Filtrage des book_table invalides
df = df.filter(~df.book_table.isin(validation_result["results"][2]["result"]["unexpected_list"]))
# Filtrage des numeros de telephone invalides
df = df.filter(~df.phone.isin(validation_result["results"][3]["result"]["unexpected_list"]))
# Filtrage des notations invalides
df = df.filter(~df.rate.isin(validation_result["results"][4]["result"]["unexpected_list"]))
Dans cette première partie, nous avons examiné ensemble un exemple d’utilisation de Great Expectations pour effectuer un nettoyage de données.
Pour le second cas d’usage, je vais procéder à une vérification de l’intégrité des données traitées dans le use case actuel.
Cas d’usage 2 - La validation de l'intégrité des données.
Objectifs
Valider que le nettoyage de données a bien éliminé les enregistrements concernant les restaurants :
- Qui n’acceptent pas les commandes en ligne
- Qui n’acceptent pas les réservations par téléphone
- Dont le numéro de téléphone et l’URL de la page Zomato sont invalides
Démarche
Afin de valider l’intégrité de mes données, je vais charger le dataset nettoyé précédemment et refaire les mêmes étapes.
1. Chargement du dataset transformé & application des attentes
Nous procédons ici de la même manière qu’au paragraphe 3) Nettoyage des données précédent :
2. Validation de l’intégrité des données
On affiche enfin le résultat le rapport HTML de résultat des validations :
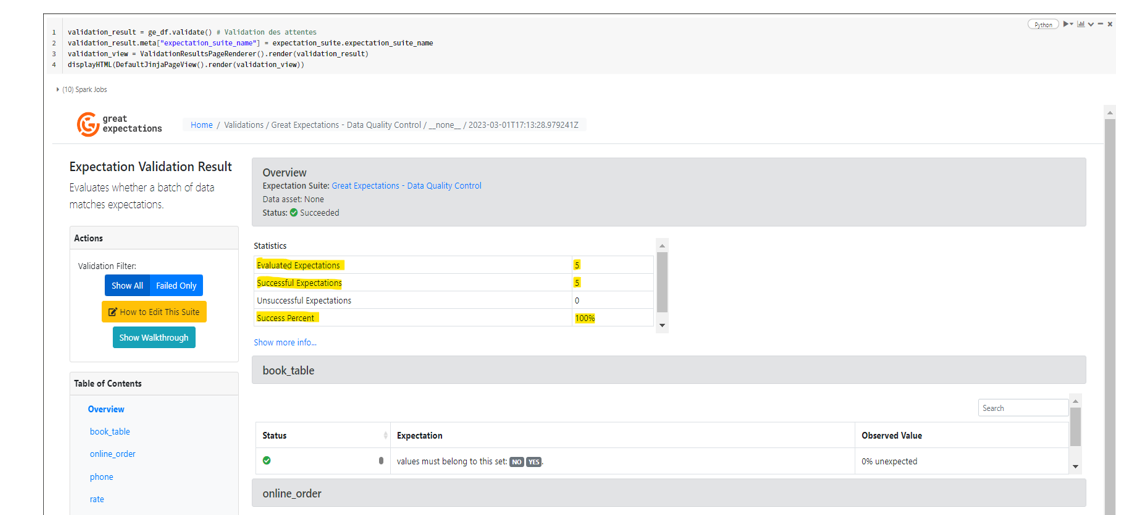
Vous remarquez que la donnée est désormais qualitative et répond aux attentes métiers définies au préalable.
Dans cet article, je vous ai présenté deux exemples courants de l’utilisation de Great Expectations pour vérifier la qualité des données dans le cadre d’un processus ETL. Cet outil s’avère être très pratique pour garantir la fiabilité des données après chaque modification.
Afin de suivre l’évolution quotidienne des données et d’effectuer des plans d’action automatisés en cas de non-conformité, il est important d’intégrer des rapports de validation de données. Dans un prochain article, je vous expliquerai comment industrialiser vos processus ETL en utilisant Great Expectations au sein d’un environnement Azure et Office 365.